本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
研究会: EMNLP
年度: 2023
キーワード: LLM, multi-modal, Demo
URL: https://arxiv.org/pdf/2306.02858.pdf
DOI: https://doi.org/10.48550/arXiv.2306.02858
コード: https://github.com/damo-nlp-sg/video-llama
データセット: MSR-VTT, MSVD, VideoInstruct, ActivityNet-QA
概要
ビデオ中の動画と音声を理解できるVideo-LLaMAを提案
Video Q-Former (BLIP2)とAudio Q-Former (Imagebind)を用いて,動画のシーン間の変化を捉えたり,audio-visualな情報を統合したりする
Video-LLaMAは動画を理解して,ビデオ中の動画や音声に基づいた意味のある応答を生成できる
提案手法
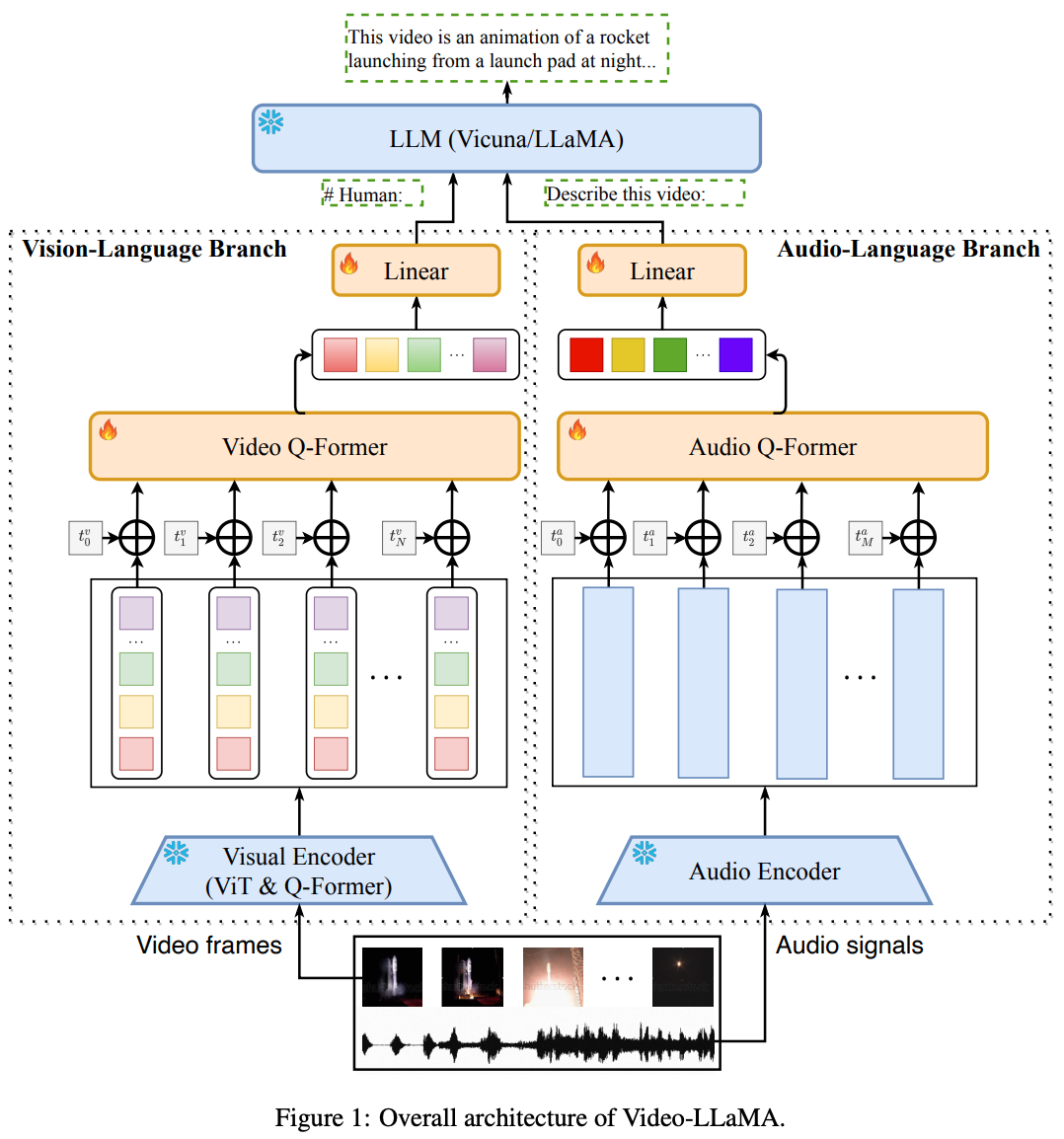
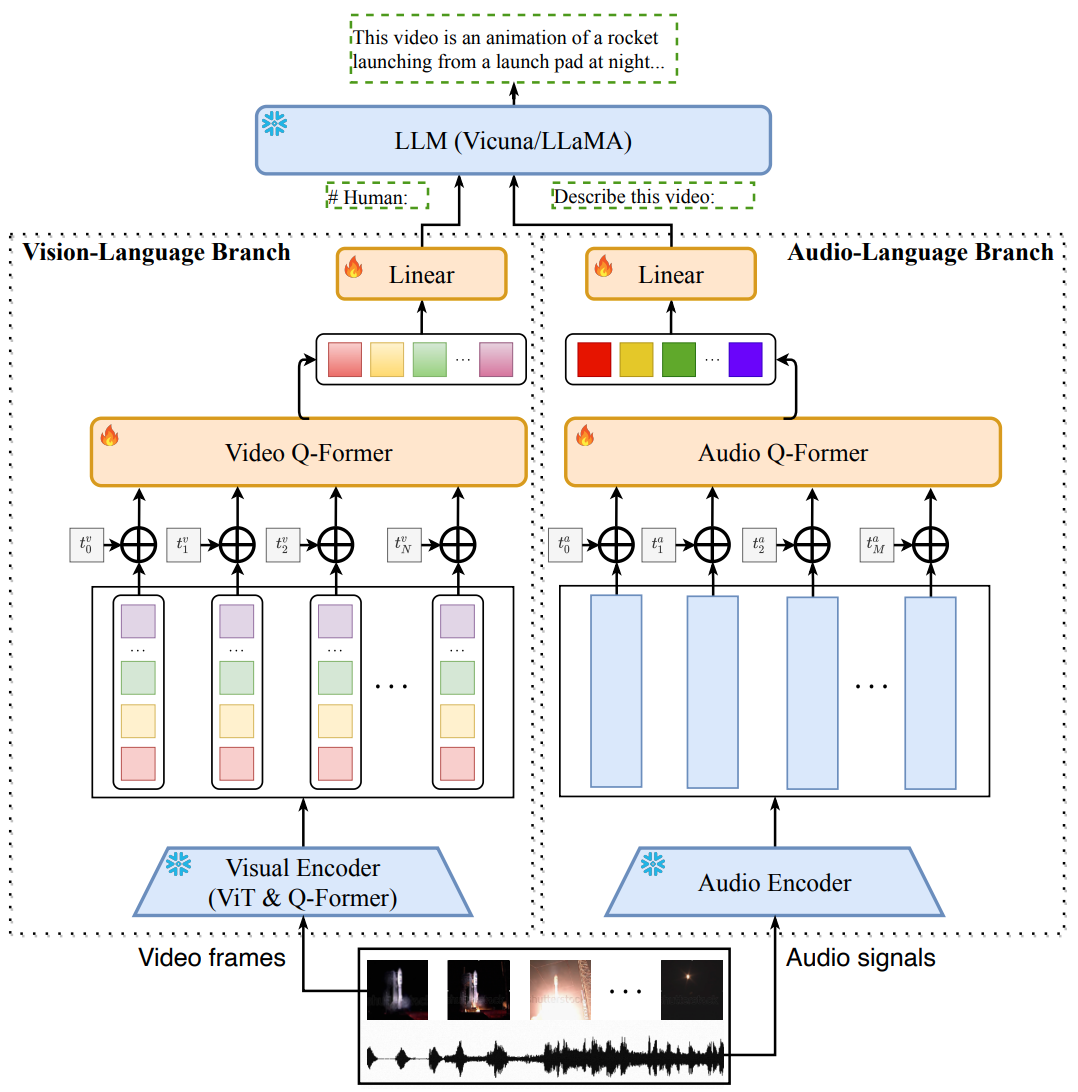
Architecture
図の通り,Vision-Language BranchとAudio-Language Branchに分岐
Vision-Language Branch
- 各フレームをフリーズしたBLIP2に入力(EVA-CLIPのViT-G/14とpre-trained Q-Former)
- positional embeddingを適用
- Video Q-Former
- 線形層
- LLMへ
Audio-Language Branch
- 2秒ごとに音声をクリップ
- 各クリップ音声を128 binsのメルスペクトログラムに変換
- Imagebind (as Audio Encoder)
- Imagebindの出力に対して,learnableなpositional embeddingを加算
- Audio Q-former
- 線形層
- LLMへ
Multi-branch Cross-modal Training
Vision-Language Branchの学習
事前学習→インストラクションチューニング
事前学習データセット:Webvid-2M,CC595k(CC3Mからフィルタされたもの)
インストラクションデータセット:MIniGPT4,LLaVA,Video-Chat
インストラクションチューニングすると,Video-LLaMAは良い能力を発揮
Audio-Language Branchの学習
audio-textなデータが少ないことが課題
→異なるモダリティを同じ埋め込み空間にalignmentするImagebindをAudio Encoderとして用い,visual-textデータを使って学習
音声データで学習しないが,推論時は音声を理解することができる
新規性
- 与えられたビデオの動画と音声を同時に処理して,会話ができるVideo-LLaMAを提案
- vision-language alignmentとaudio-language alignmentの両方を達成するmulti-branch cross-modal pre-training frameworkを提案
Examples

動画と音声の両方を理解できている例
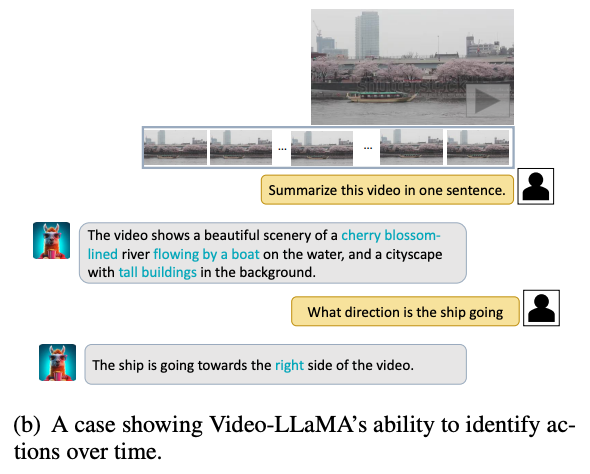
Temporal dynamicsを理解できている例

staticな画像を理解できている例

一般的な知識を示せている例
chat形式の例は論文のappendixを参照
まとめ
動画と音声を理解できるVideo-LLaMAを提案
Vision-Language BranchとAudio-Language Branchで分岐して,動画と音声を理解するアーキテクチャを提案し,Imagebindをvisual-textデータで学習することでaudio-textデータの少なさをカバー
Hallcinationがあることや,映画やテレビのような長い動画を処理できないことがlimitaitions
その他
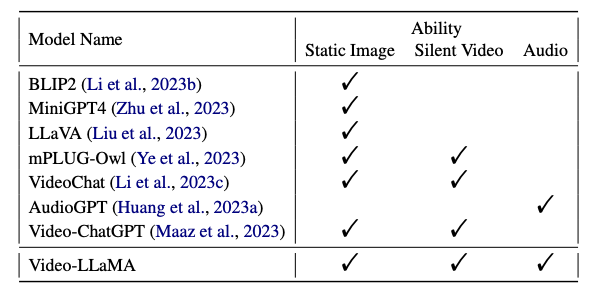
ポピュラーなマルチモーダルLLM
所感
Imagebindで同じ埋め込み空間に異なるモダリティの埋め込みを押し込んでいるのを利用して,audio-textデータの少なさをカバーしているのが上手いのだろうが,それでうまくいくことにちょっと気持ち悪さが残った(個人的に,大規模なaudio-textデータ構築へのモチベがより大きくなるなど)
素人感想だと,Audio-Language BranchにImagebindを使うのなら,Vision-Lannguage BranchもImagebindで良いのでは?と思った
とはいえ,temporalな情報をLLMで扱う手法はかなり参考になる
次読みたい論文
ImageBind: One Embedding Space To Bind Them All
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
引用
@article{zhang2023video, title={Video-llama: An instruction-tuned audio-visual language model for video understanding}, author={Zhang, Hang and Li, Xin and Bing, Lidong}, journal={arXiv preprint arXiv:2306.02858}, year={2023} }