本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Transformerによるhallucination errorの事後修正
研究会: NLP
年度: 2022
キーワード: dialogue system
URL: https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/B2-5.pdf
データセット:
概要
文生成時に与えた外部知識と異なる内容の発話文を生成してしまうhallucination errorが課題
→ hallucination errorを含むデータを疑似的に作成し,BARTやTransformerを用いて事後修正を試みる
1.6BのTransformerでは52件中29件の事後修正をした
提案手法
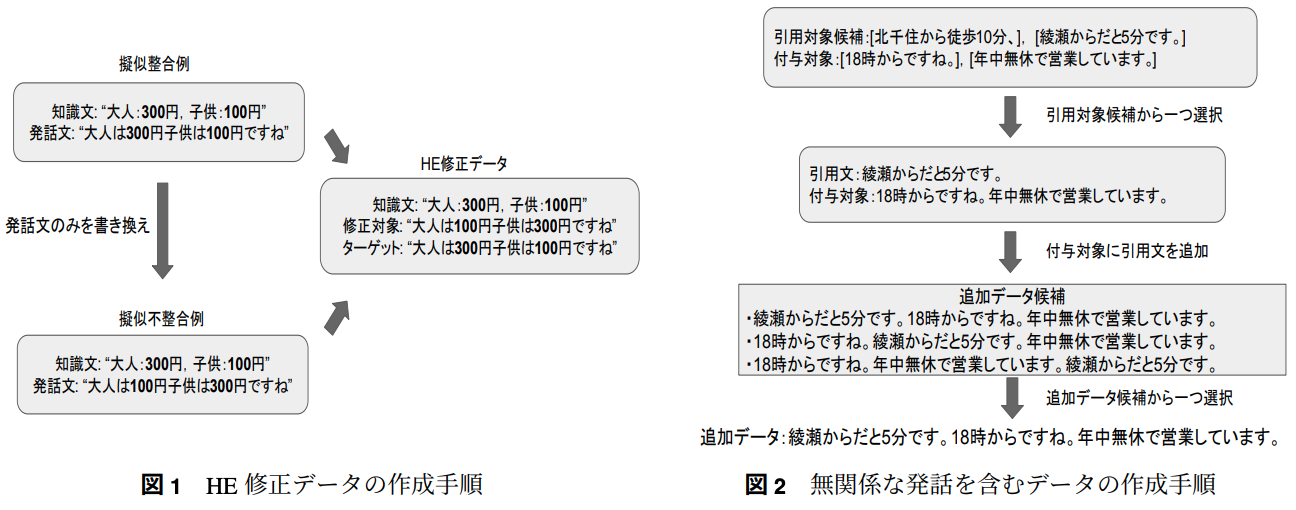
一つの発話文と知識源のペアをテンプレートとして複数のデータを疑似的に作成することで,各知識とカテゴリごとに40000件の発話ぶんと知識源のペアを作成
→ 「営業時間」「アクセス」「料金」に関するエンティティを書き換えることで疑似的なhallcination errorを含んだ文を作成
ニューラル生成モデルは事実と無関係な文章を生成する場合がある
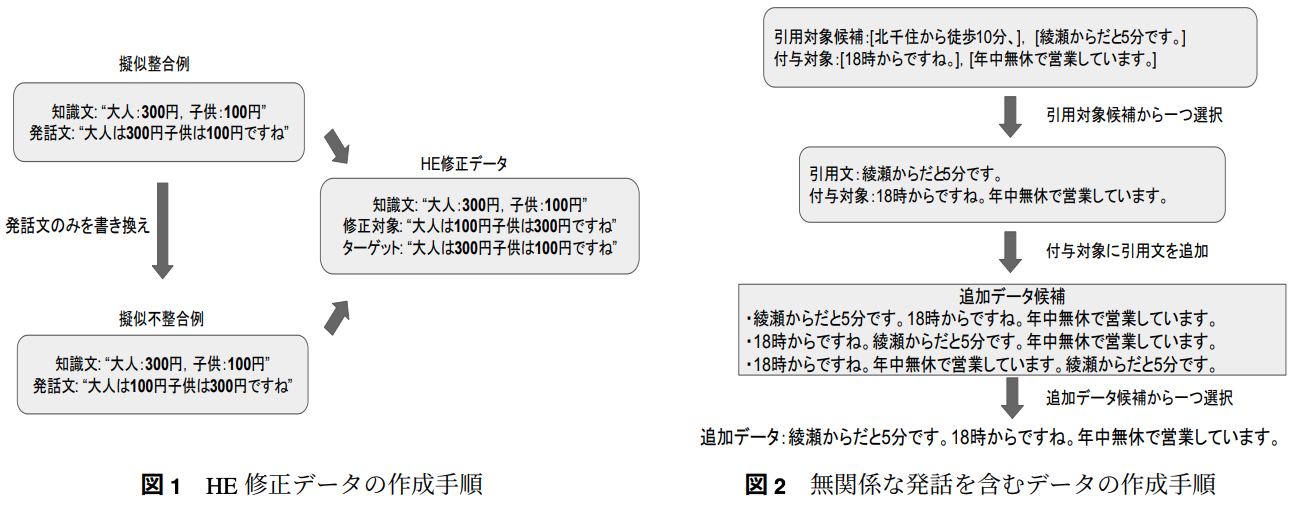
→ エンティティの書き換えだけではなく,無関係な発話を含んだデータも作成
新規性
hallucination errorを含むデータを疑似的に作成することで,ニューラルモデルによる事後修正の試み
実験
NTT製japanese-dialog-transormers(1.6B)
黒橋研製日本語BART(0.12B)
hallucination error修正学習データセットには,無関係な発話を含む(add_unrelated)とそれを含まない(baseline)データセットを二種類用意
※知識源とHEを[SEP]でつなげるが,普通はBARTは対応していないのでfairseq上ではFusion-in-DecoderをBARTに実装する必要があるらしい
評価指標
Faithfulness/BLEU-4 score
まとめ

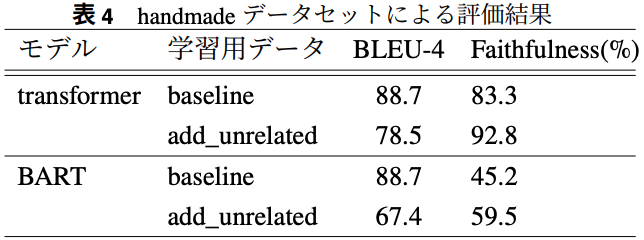
BLEU-4は「数値が異なる」みたいな単純なhallucination errorは正しく評価できていないのでは?
BARTとTransformerの大きな精度差はおそらくパラメータ数と事前学習時のデータセットの差なのでは?
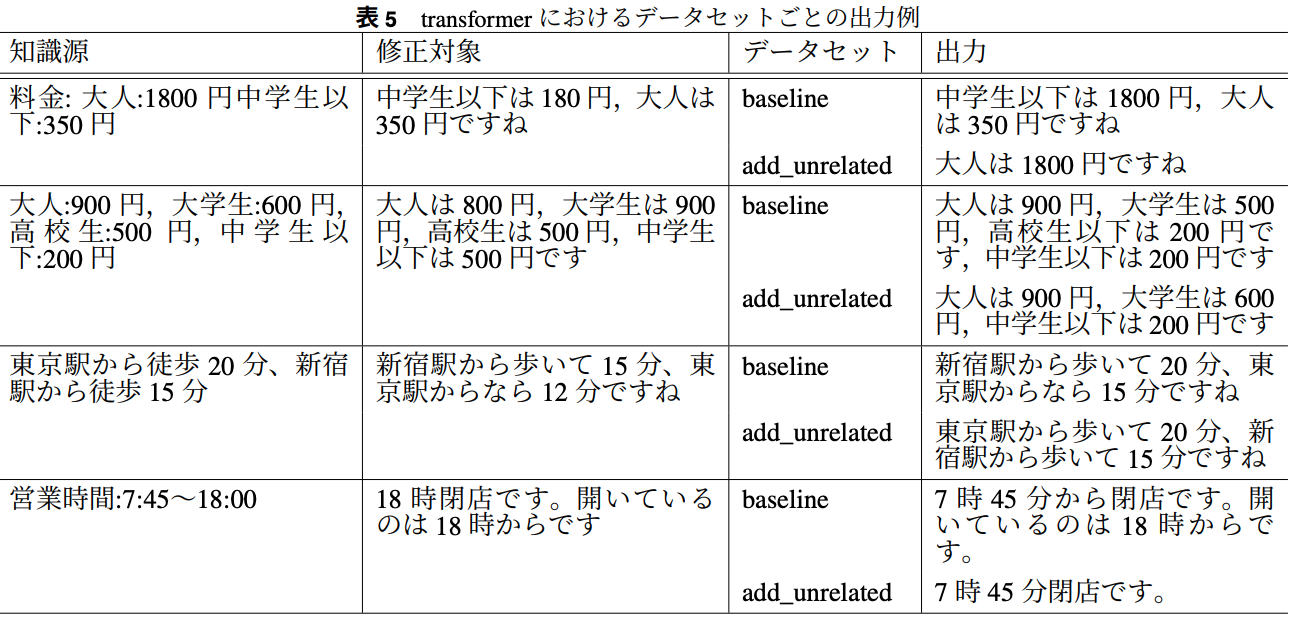
知識源に出現するエンティティの順序とモデルの主直に出現するエンティティの順序が同じ
→ エンティティが出現する順序に注目して書き換えを行っている可能性
正しくエンティティの関係を理解できていない?
add_relatedでは発話ぶんにある一文を削除する傾向が見られた
その他(なぜ通ったか?等)
今後の展望
HE修正学習データセットの基となるデータの収集
書き換えルールなど作成方法の拡張の必要性