本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Recent Neural Methods on Dialogue State Tracking for Task-Oriented Dialogue Systems: A Survey
研究会: ACL SIGDIAL
年度: 2021
キーワード: dialogue system, survey, DST
URL: https://aclanthology.org/2021.sigdial-1.25.pdf
データセット:
Data State Tracking (以下DST) on Task-Oriented Dialogue Systemに焦点を当てたsurvey
Abstract
触れること
- タスク
- データセット
- evaluation metrics
- アプローチ
本論文では,二つのDSTモデルをしっかり区別する.
- static ontology DST models
- 固定された対話状況集合を予測する
- dynamic ontology DST models
- オントロジーが変化した時でも対話状況を予測する
Definition of ontology
a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
単一ドメインでも複数ドメインでもトラックすることや新しいドメインにスケーリングすることのモデルの性能について議論する
Terms: knowledge transfer, zero-shot learning
カバーしている年代は2013~2020
Introduction
Task-oriented dialogue system:
ユーザーがタスクを成し遂げるようにするシステム
チケット予約,レストラン予約,カスタマーサポートなど
ユーザの要求を正確にトラッキングする性能は,一貫していて効果的な対話を可能にする
対話状況をslot-valueで表現するDSTコンポーネントを使った情報をトラッキングする
↑この精度がとても重要で,下流のコンポーネントがこの状況を利用して,次のactionを決定する
DSTタスクは,実際Natural Language Understanding (以下NLU)のタスクを統合している
ただし,単なるslot filling taskよりも複雑になっている
DST
現在のturnまで,対話レベルでslot-valueを予測
Slot Filling
特定のturnのみ考慮してslot-valueを予測すれば良い
モデルとしては以下が提案されている
RNN-based models
Attention-based models
Transformer-based models
ここ最近では,単一ドメインではなく,マルチドメインやflexibleにドメインの移行をするモデリングの研究が盛んらしい
Dialogue State Tracking
そもそもDSTとは
Dialogue State
→turn
次の行動を決定するための全ての十分な情報を含んでいる
slotはOntology
valueはユーザによって与えられた各スロット
レストランの例で言えば
slotのタイプは二つ
-
informable 対話から得られる→FOODやAREA
-
requestable システムが与える→ADRRESSやPHONE
Dialogue State Tracker
-
turn-level prediction 各ターンで与えられるslot-valueを予測
-
dialogue-level prediction 各ターンでの完全な対話状況を予測
Turn-level prediction
直近のturn
rule-basedの場合は,そのルールに従って,
turn
確率を利用して統合したり
learning to updateの場合は,turn-levelの予測を入力として,対話状況を予測する方法を学習する
Dialogue level prediction
各turn
直前の対話状況
Datasets
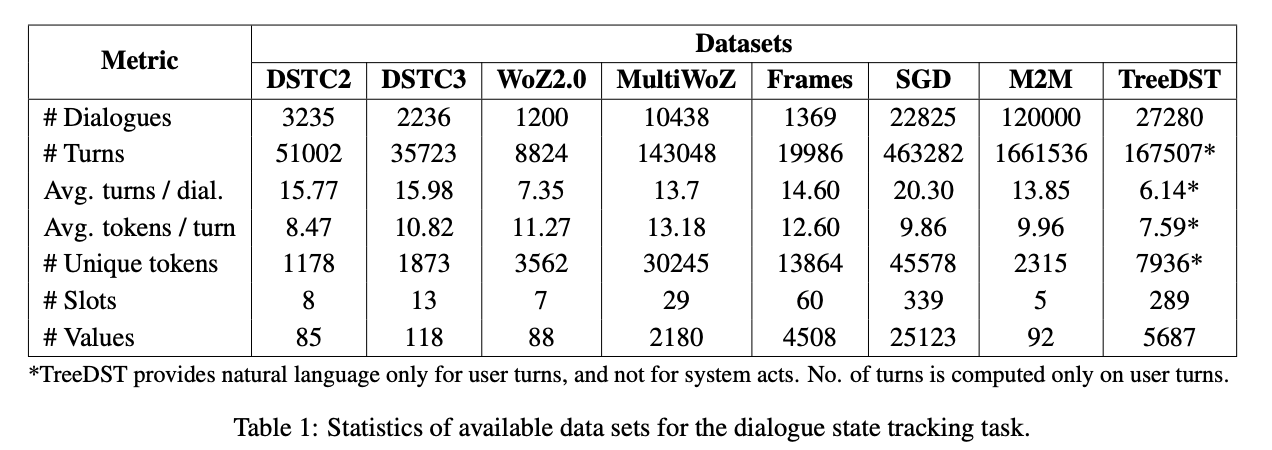
- Dialog State Tracking Challenge (DSTC)
- DSTC2 and DSTC3
- WoZ2.0
- MultiWoZ
- Schema-Guided Dataset (SGD)
- TreeDST
- Machine-to-Machine (M2M)
Evaluation Metrics
- Average Goal Accuracy
- Joint Goal Accuracy
- Requested Slots F1
- Time Complexity
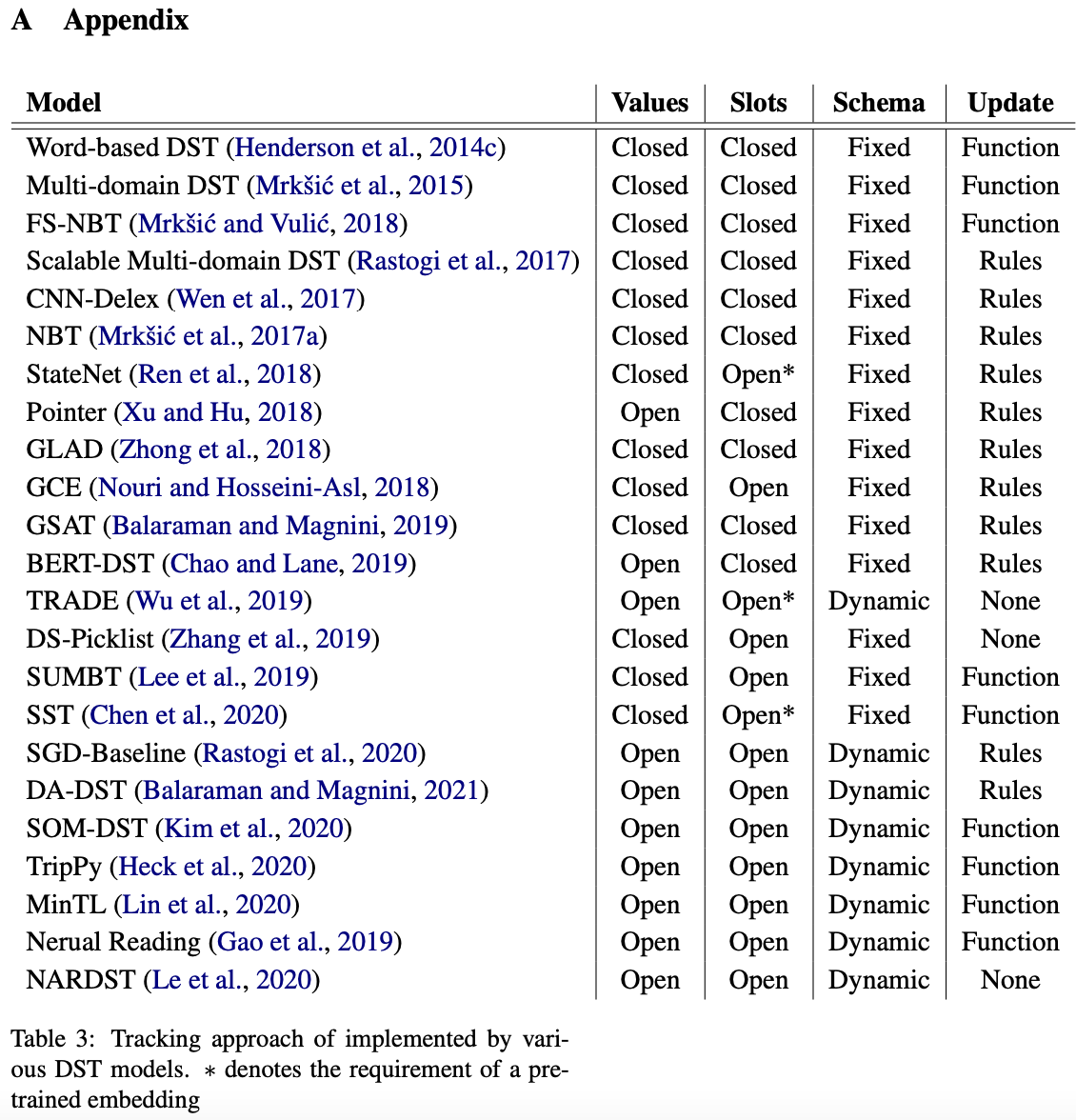
Static Ontology DST Models
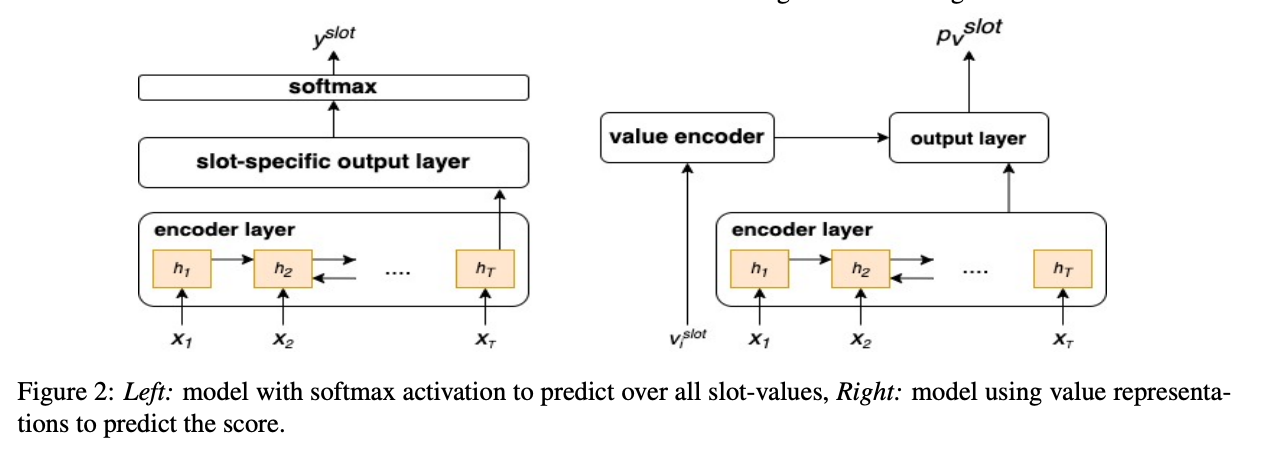
slot-valueは事前に定義されている
→
output layerは
- feed-forward layer - slotとvalueが固定なので,それらはembeddingされているため可能
- softmax - 全てのslot-valueのペアの確率を求める
- sigmoid - それぞれのslot-valueの確率を求める
Delexicalization
imbalanced training data for slot-valuesに対処する効果的なアプローチ
入力のslot valuesをラベルの名前に置き換える
I want Chinese food.
→ I want F.VALUE F.SLOT.
Data-driven DST
delexicalizationは確かに効果的だが,手作業でのfeature engineeringが必要になる
→ data-drivenな手法が提案された
Parameter sharing
昔のモデルはslotごとにエンコーダが分かれていた
→そのため全てのslotに対してパラメータを共有する手法が提案された
StateNet?
RNN and latency in DST
予測時間が問題だったため,それに対する対策の提案
Encoder based on pre-trained LM
BERTなどを使うことで,捕捉できるslot valueが増えた
Dynamic Ontology DST Models
オントロジーが事前定義されていなくてもslot-valueをトラッキングする必要がある
アプローチは2種
- ユーザの入力からslot-valueをコピー
- outputにslot-valueを生成
下図は2種のアプローチを合わせたアーキテクチャ
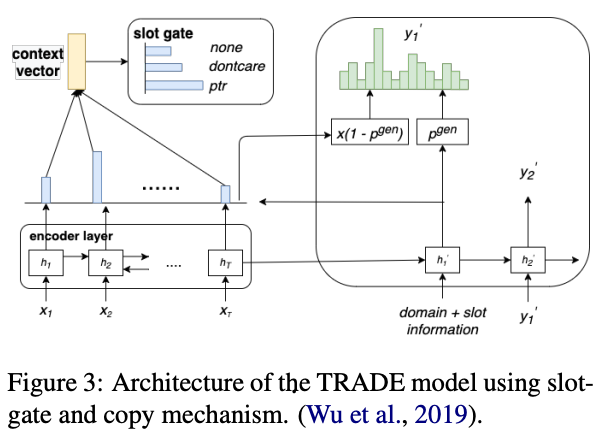
static ontology vs dynamic ontology
staticだとvalueが有限だが,
dynamicだとoutputの語彙数がとても大きくなる
Copy and pointer networks
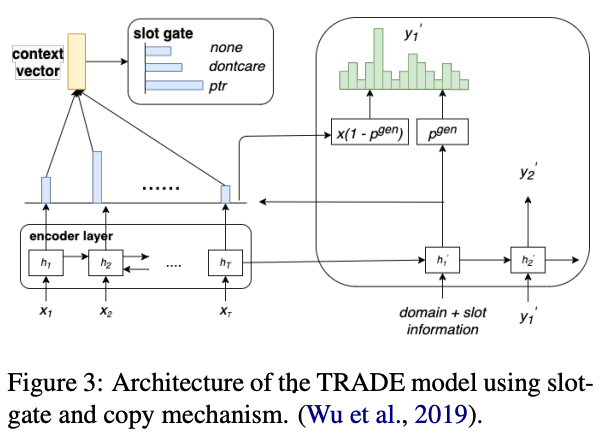
copy mechanismとpointer networkがメインのアプローチ
どちらもattention-based
Xu氏とHu氏が提案したpointer networkベースのアーキテクチャだと,すべてのslotには適用できず,postprocessingが必要だった
→ Wu氏がTRADEというモデルを提案
全てのslotとdomainに関する全てのパラメータを共有していて,domain transferができるらしい
zero-shotアプローチと言える
Categorical and non-categorical slot-values
non-categoricalなslotは,オープンなvalue集合を受け入れることができる
Zhang氏が提案した手法によれば
もしcategoricalのラベルがついていれば,outputは事前定義されたvalueに対する確率のスコアを出力
non-categoricalであれば,outputにはinput tokenからデコードされたものを出力
Heck氏は,TripPy (triple copy strategy)を提案
シナリオに応じてslot-valueを予測する
- ユーザに明示的に示された
- システムに示され,ユーザによって言及された
- 別のドメインのslotのために前の対話ターンにおいて示された
Function-baed update
CARRYOVER: 前の対話状況を引き継ぐ
DELETE : slot-valueを戻す
UPDATE : slot-valueの予測を必要とし,対話状況を更新する
Take-away Points
- 各スロットに多様なモデルを使うのは,汎化性能や効果的な表現を学習するのに限りがある
- スロット間のパラメータシェアリングは効果的で,全てのスロットに対するパフォーマンスを改善する
- 大規模データセットを使うと,RNNはSOTAの性能が出る
- RNNは,encoderとdecoderを両方使うと時間がかかる問題がある
- attention-basedのcopying mechanismは効果的なアプローチであり,多くのSOTAモデルで採用されているアプローチ
- 小資源のドメインに対しては,事前学習済みの言語モデルを使用することで性能がよくなる
- 統計的な更新関数はルールベースの更新関数を超える性能を出す
- ドメインのスケーラビリティとモデルの柔軟性が問題の時,scheme-basedアプローチを使うとscheme内での変更を入れることが可能になる
- zero-shotを含むtransfer learningが可能に
- DSTモデルの大半は,事前学習済み言語モデルが使われている
DST Challenges and Future Directions
現実世界の会話アプリにおいて新たなslotやdomainの追加は避けられない
Few-shot and Zero-shot Models
Data Augmentation and Data-efficient Models
Diverse Datasets
引用
@inproceedings{balaraman-etal-2021-recent, title = "Recent Neural Methods on Dialogue State Tracking for Task-Oriented Dialogue Systems: A Survey", author = "Balaraman, Vevake and Sheikhalishahi, Seyedmostafa and Magnini, Bernardo", booktitle = "Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue", month = jul, year = "2021", address = "Singapore and Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2021.sigdial-1.25", pages = "239--251", abstract = "This paper aims at providing a comprehensive overview of recent developments in dialogue state tracking (DST) for task-oriented conversational systems. We introduce the task, the main datasets that have been exploited as well as their evaluation metrics, and we analyze several proposed approaches. We distinguish between static ontology DST models, which predict a fixed set of dialogue states, and dynamic ontology models, which can predict dialogue states even when the ontology changes. We also discuss the model{'}s ability to track either single or multiple domains and to scale to new domains, both in terms of knowledge transfer and zero-shot learning. We cover a period from 2013 to 2020, showing a significant increase of multiple domain methods, most of them utilizing pre-trained language models.", }