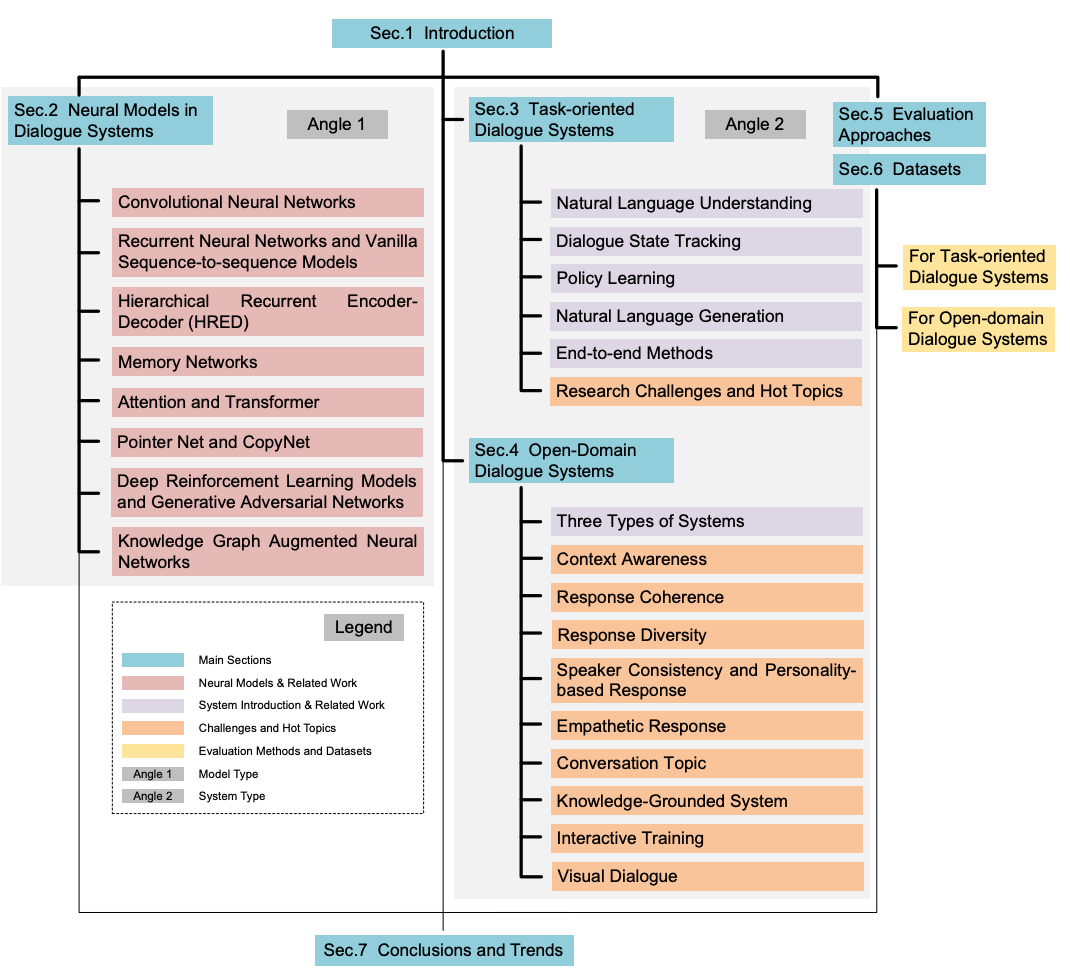
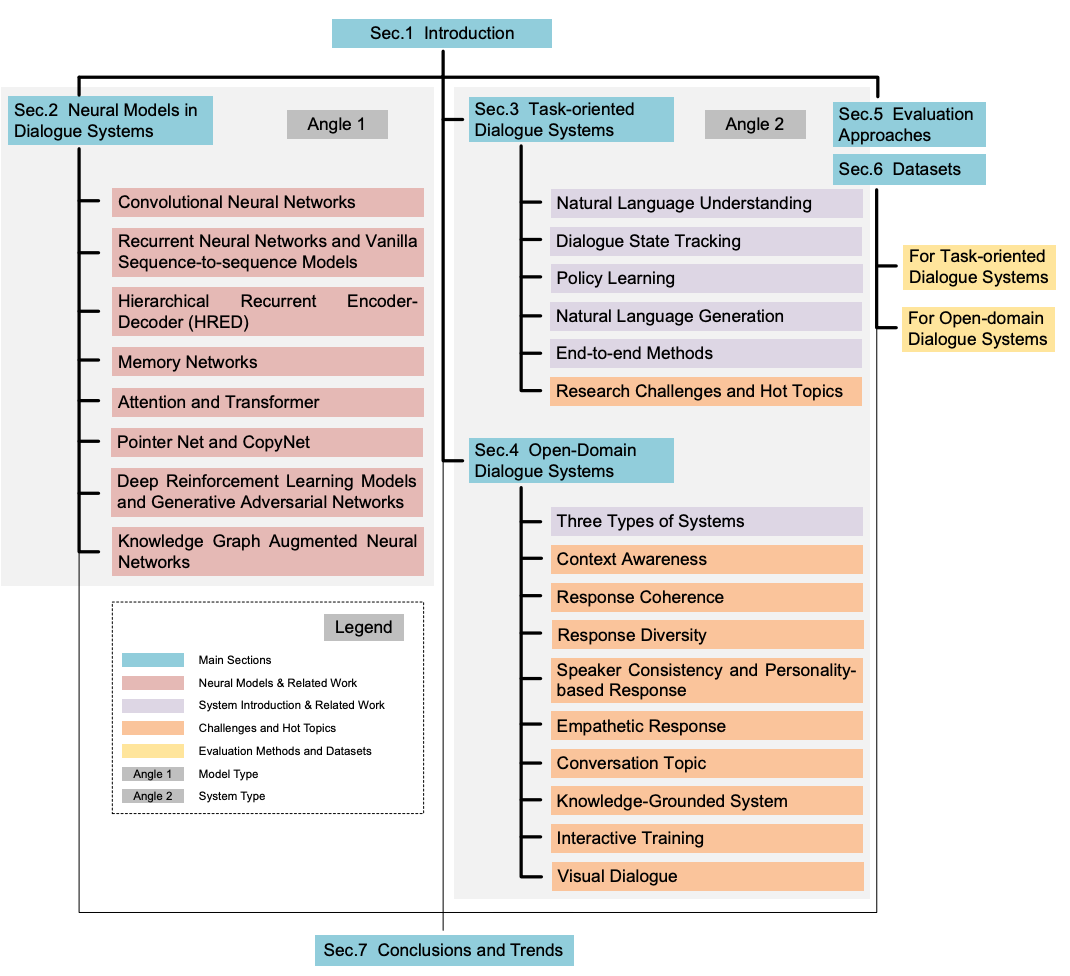
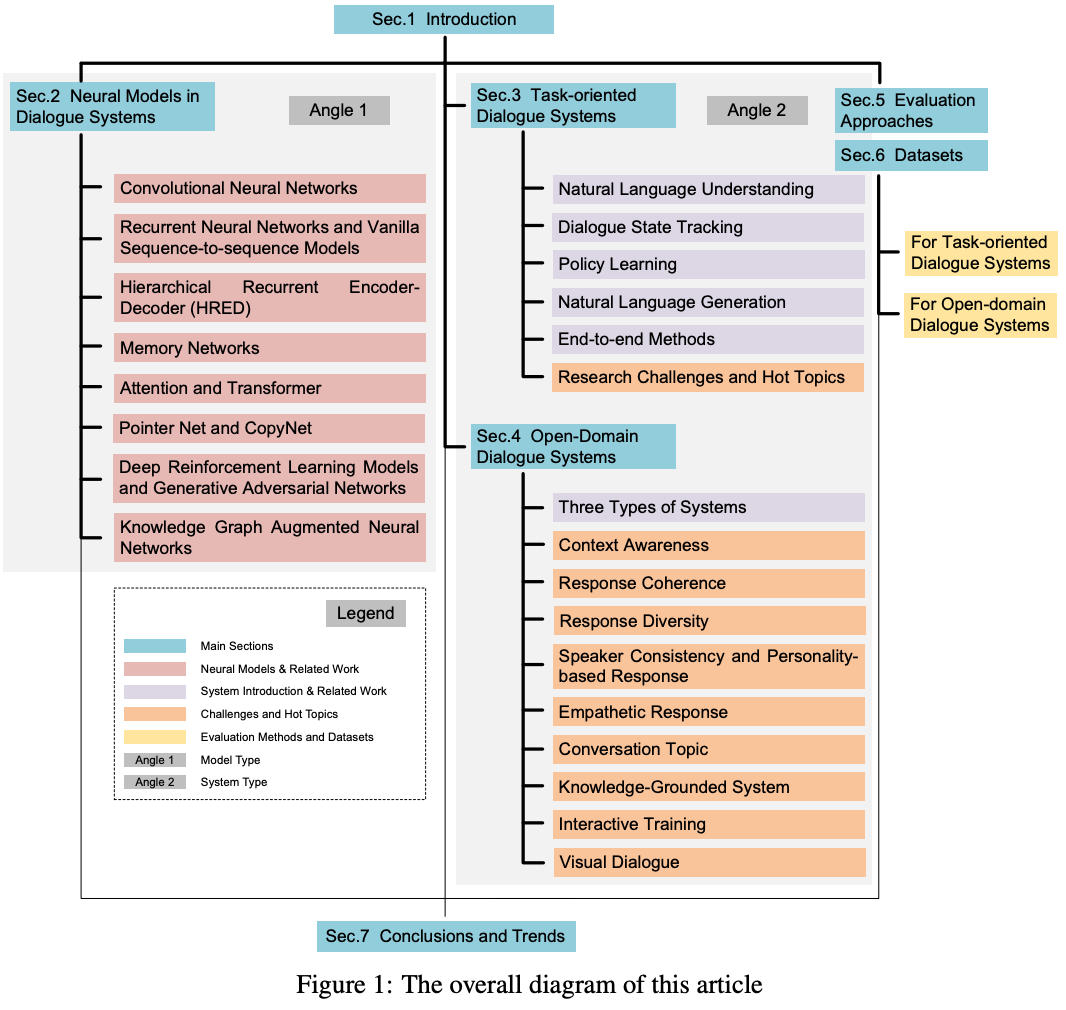
本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey
研究会: arxiv
年度: 2021
キーワード: survey, dialogue system
URL: https://arxiv.org/pdf/2105.04387.pdf
データセット:
概要
対話システムに関するサーベイ論文
対話システムはNLPタスクの一種
研究の価値が高いNLPタスクを多く含むため,対話システムは複雑と言える.
ここ最近で良い成果をあげているもののほとんどがDL
メインは,モデルタイプとシステムタイプについて述べられる.
システムタイプ
タスク指向型
オープンドメイン型
Keywords

サーベイの主張の流れ
まとめ
Introduction
対話システムはNLPにおいてホットな話題であり,産業においても需要が非常に高い.
タスク指向型とオープンドメイン型の対話システムが存在する.
昔ながらのタスク指向型は,Natural Language Understanding, Dialogue State Tracking, Policy Learning, Natural Language Generationの4つからなっていた
⇒
最近のSoTAモデルでは,E2Eのタスク指向型の対話システムが多い.
オープンドメイン型
- generative systems
- seq2seqなモデル
- ユーザのメッセージや対話履歴を返答系列にマッピングする(Trainingデータに存在しないであろうものも含む)
- 柔軟でコンテクストを読んだ返答をするが,時々主張が一貫しない返答や鈍感で面白くない返答を返す.
- retrieval-based systems (検索)
- 返答の集合の中から,すでに存在する適した返答を探す.
- 表面上では良い返答をする.ただし,返答集合は有限集合なので,対話上のコンテクストに対しては関係性があまりみられないこともある.
- ensemble systems
- 上記二つを含む
- Generatie systemsは検索システムをよくするために使われる.
- 検索システムはより適した返答を選ぶために使われる.
古典的な対話システムとして,finite state-basedとstatistical learningとmachine learning-basedが挙げられる.
- Finite State-based
- 対話の流れはあらかじめ決められている
- 決まったシナリオの中でしか対応ができない.
- Statistical Learning-based
- Finite State-basedよりは柔軟である.あらかじめ対応が決められていないから.
- machine learning-based
- Deep learningが主流?
NLPの中には対話システムに近い領域がある.
- Q & A
- reading comprehension
- dialogue disentanglement
- visual dialogue
- visual Q & A
- dialogue reasoning
- conversational semantic parsing
- dialogue relation extraction
- dialogue sentiment analysis
- hate speech detection
- MISC detection (???)
Neural Models in Dialogue Sustems
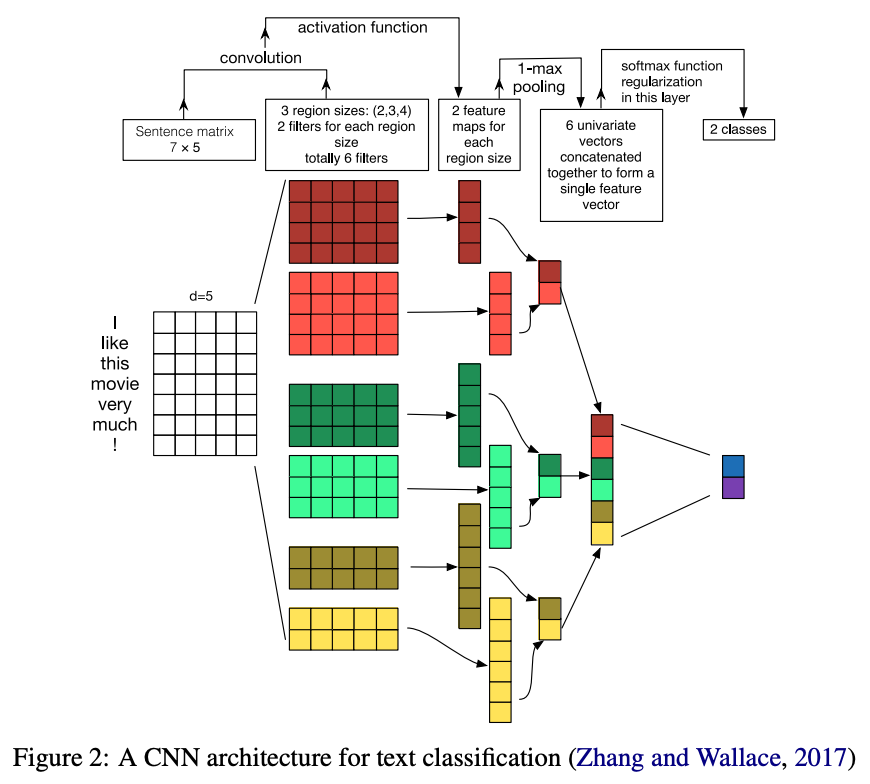
- CNN
- ここ数年NLPの分野での応用も多いらしい
- フレーズや文章,パラグラフには意味づけをするのに有用でCNNがヒラルキーなモデルになる
- CNNは一条に乏しいため,最近のSoTAにおいては,テキストをencoderにかけたのちにCNNを用いてヒエラルキーな特徴抽出を行っている.
- 欠点として入力系列の長さは固定長のため以下の使用例
- encoderの出力をCNNでベクトル化
- contextと返答の候補を行列にして,CNNで近さを図ることによって,妥当な候補を選び出す
- 基本的にCNNとencoderはセットか?
- RNN and Vanilla seq2seq
- 系列として扱えるのが利点と考えるべき
- HMMや古典的な系列モデルだと,推論時のアルゴリズムの複雑さや考えるべき状態空間の増大に合わせて行列サイズが大きくなりすぎて,大きな状態空間を必要とするデータには対応しがたい.
- マルコフモデルは限られた条件下においては強力なモデルになりうる.
- RNNは最近では提案されないが,NLPタスクにおいては未だ現役として活躍することもある
- Jordan-Type & Elman-Type RNN
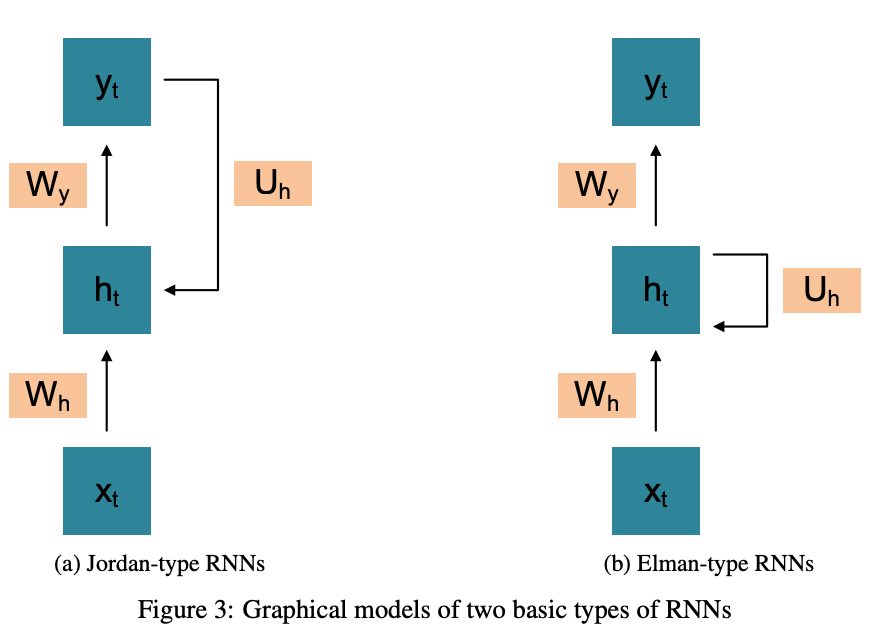
- Jordan-Type RNN
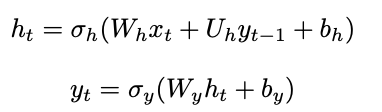
- 最新の隠れ層の状態は,Input_tとOutput_t-1による
- Elman-Type RNN
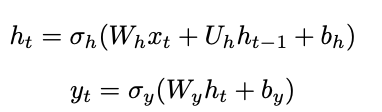
- 最新の隠れ層の状態は,Input_tとHidden_t-1による
- いずれにしてもシンプルなRNNは勾配消失か勾配爆発が大抵おこる
- LSTM
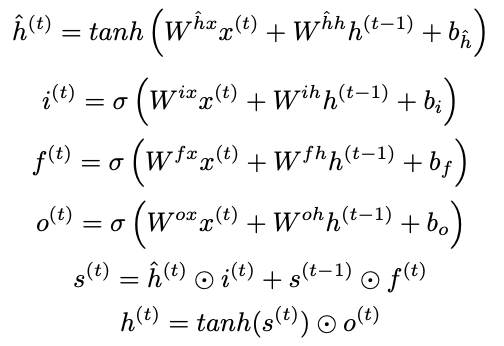
- Gates
- 入力ゲート
- 忘却ゲート
- 出力ゲート
- GRU; Gated Recurrent Unit
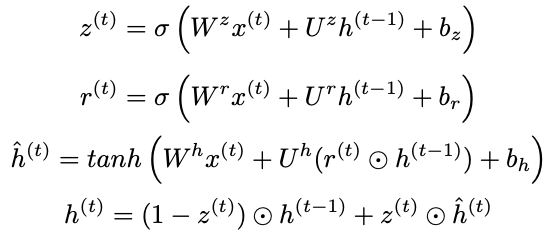
- Gates
- 更新ゲート
- リセットゲート
- パラメータが少ないため,
- 早い
- 汎化性がみられる
- ただし,
- 大きなデータセットには対応しきれないこともある
- Bi-directional RNN
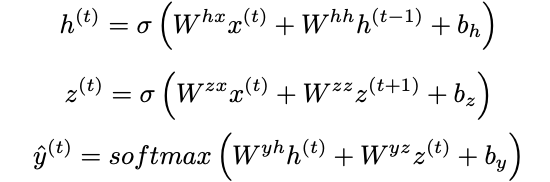
- 双方向を考慮したRNN
- seq2seq; Encoder-Decoder model
- 初めは機械翻訳のために提案された手法
- Encoderにより入力系列をベクトル化,その隠れ状態をDecodeして生成することを目指す
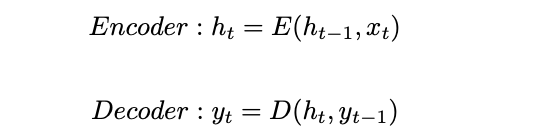
- Encode時
- t時刻のinputとt-1時刻のhiddenによって,t時刻のhiddenが決まる
- Decode時
- t時刻のhiddenとt-1時刻のoutputによって,t時刻のoutputをデコードする
- 入力系列と出力系列の長さが固定長である必要はない.
- その代わり,適応させる系列長と出力される系列長は同じになることは保証されない
- Hierarchical Recurrent Encoder-Decoder; HRED
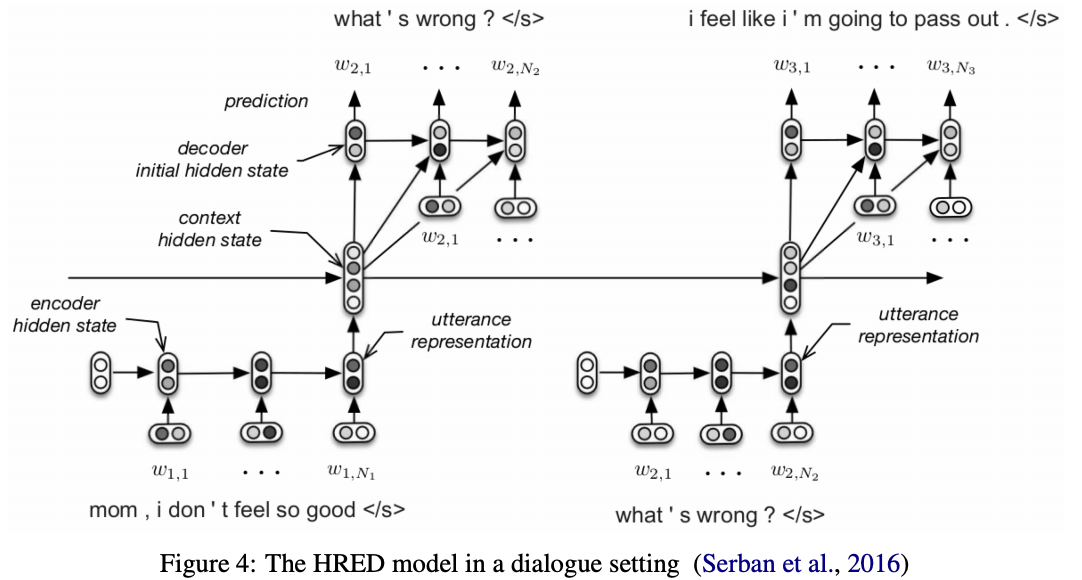
- コンテクストを理解するためのseq2seqモデル
- クエリの履歴を理解する?
- トークンレベルとターンレベルで学習する
- Memory Networks
- Attention and Transformer
- Attention
- Transformer
- Muti-head Attention
- Pointer Net and CopyNet
- Pointer Net
- CopyNet
- Deep RL and GANs
- Deep Q-Networks
- REINFORCE
- GANs
- Knowledge Graph Augmented Neural Networks
2章は途中から読むのやめた.使用されるネットワークよりも課題感の方が知りたい.
タスク指向型対話システム
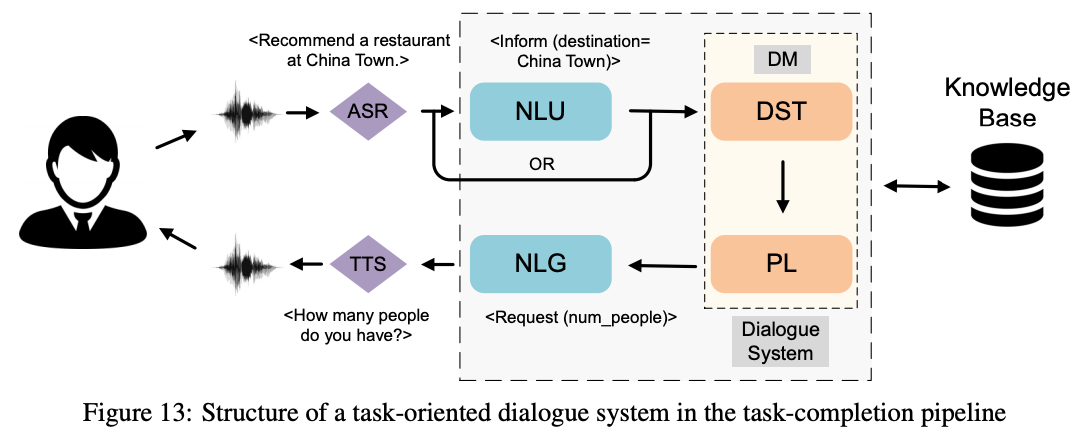
ドメインの決まったタスクにおいて特定の問題を解決する.
- Natural Language Understanding

- 3つのタスクを持つ
- ドメイン分類
- 意図の理解
- スロット埋め
- IOB; Inside Outside Beginning
- NER; Named Entity Recognition
- intent detectionにおいては,Task-Oriented Dialogue BERTがSoTA?
- Domain classification & intent detectionは同カテゴリタスク
- slot filling task = semantic tagging
- NLUタスクを解く際に,音声データをそのままInputとして与える研究事例も出ているらしい
- エラーが少なくロバストなモデルになったらしい?
- Natural Language UnderstandingとNatural Language Generationは逆のプロセスをふむ
- 同時にタスクを学習結果が得られるというアプローチも
- Dialogue State Tracking
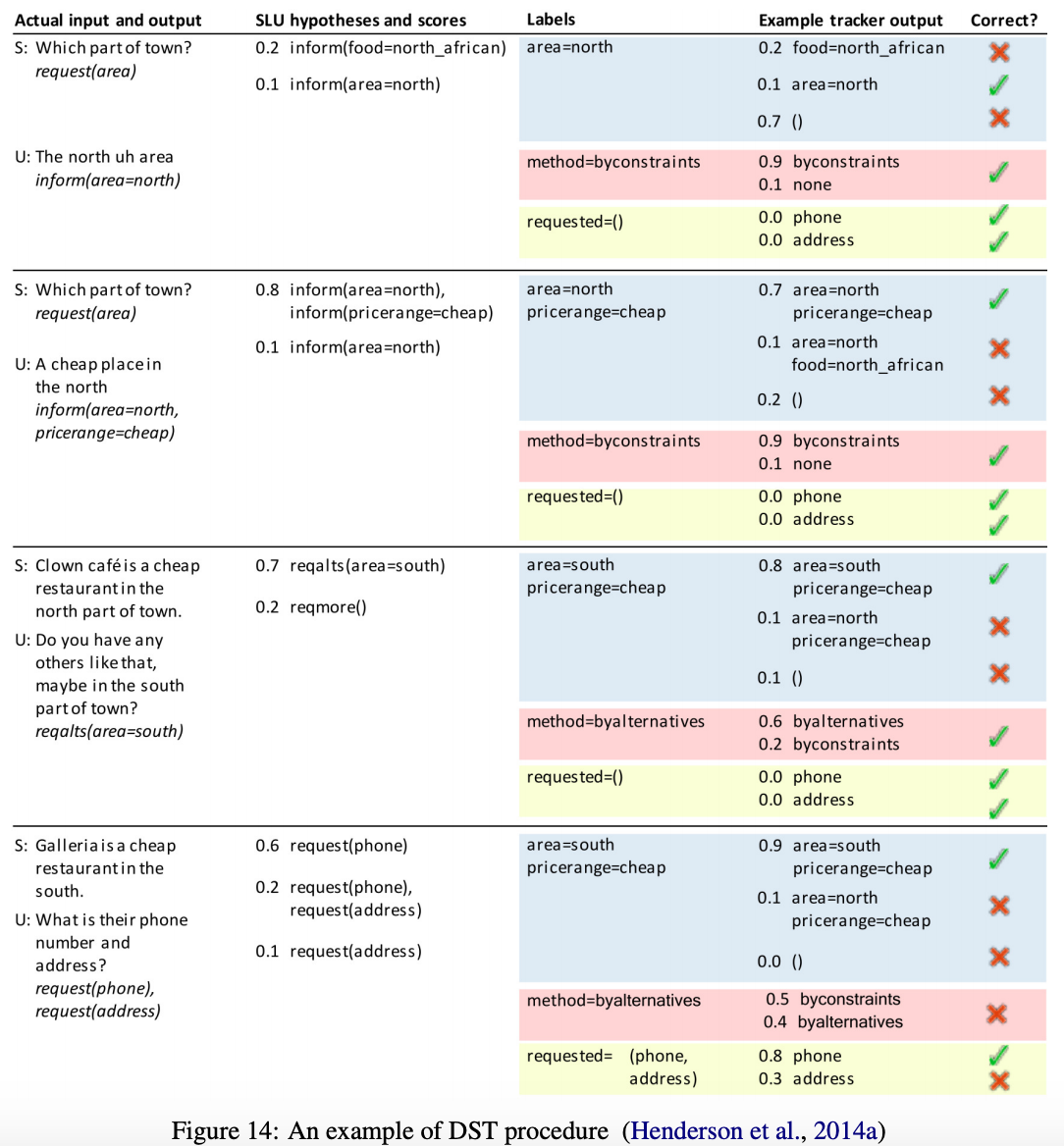
- ユーザの目的と対話履歴を追跡する
- NLUとDSTのタスクは近い関係にある.
- NLUは単語にtagを割り振っていくイメージ
- DSTはtagのplaceholderを会話の内容から埋めていくイメージ
- Dialogue Stateには3つの要素からなる
- Goal constraint corresponding with informable slots
- 特別なvalueの制約で,ユーザによって言及されるか特別な値をとる
- DontcareやNoneが特別な値にあたる
- Requested slots
- Search method of current turn
- 古典的な手法でいくと,
- ルールベースはエラーが多く,ドメイン適応が大変
- 統計的手法はノイジーな状態や曖昧性に弱い
- ニューラルネットな手法
- slot-valueのペアを事前定義して学習
- valueが大きくなると複雑性が増す
- slot-valueのペアを読むだけでよく,2値分類タスクとして解ける
- モデルの複雑性は避けられるが,反応速度が遅くなる可能性がある.
- slot-valueのペアを定義せずに,対話の中から直接選ぶ
-
Policy Learning
- DSTモジュールの出力結果からどう行動をとるか
- 教師あり学習or 強化学習
- 教師ありだとアノテショーンデータセットを作るのがとても大変
-
Natural Language Generation; NLG
- タスク指向型対話システムにおける最終層のモジュール
- 最終的な自然言語表現を生成するシステム
- 4つのコンポーネントからなる
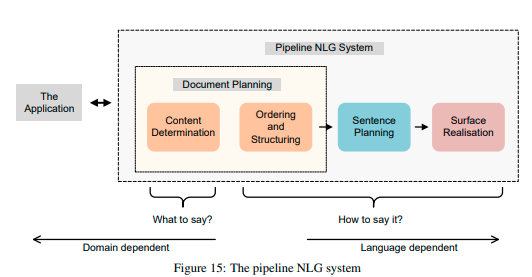
- Content Determination
- Sentence Planning
- Surface Realization
- Lexicalization, Referring expression, aggregation
- RNNに基づいた統計言語モデルにおいて,意味的制約や文法構造による返答生成を行うなど
- コンテクストを理解した返答を生成することは重要である
- タスク指向型においては,返答の多様性というよりも信頼性のほうが重要視されがち
- 意味解析をビームサーチを使うことで,意味の正しさを改善する手法も提案された
- E2E Methods
-
end-to-endのパイプラインを組むことで高いパフォーマンスを発揮することがあるが,
-
多くのモジュールを組み込むため,バックプロパゲーションで誤差が伝播しないこともある.
-
すべてのモジュールが,返答の精度を向上するために,対等に重要であるとは限らない.
-
違うドメインに差し替えるとき,オントロジーを事前学習させる必要があるため,困難が生じることもある
-
やり方は大きく分けて2つ
- すべてのモジュールを展開して誤差逆伝播させる?
- 知識ベースの検索システムと返答生成の双方を用いてパイプラインを組む
-
タスク指向型においては,外部の知識源が必要なことが多い
-
オープンドメイン型対話システム
- 雑談対話システム,或いはタスク思考型ではない対話システムのこと
- SoTAを示しているオープンドメインは大抵ニューラルネットで解決している
- 完全なるデータドリブンなものが多い
- オープンドメイン型対話システムは,大まか3つに分けられる
- 生成システム
- 検索ベースシステム
- アンサンブルシステム
3つの話が以下
- 生成システム
- 訓練コーパスに出てこないような返答に対して,ユーザのメッセージや対話履歴をマッピングするために,seq2seqなモデルを適用する
- 検索システム
- 決まった返答集合の中からすでに存在する返答を探そうとする
- アンサンブルシステム
- 生成手法と検索手法を合わせる.
- 生成された返答と検索された返答とを比べる.
- 生成も,検索された返答を洗練するために用いられる.
特徴として,
生成モデルは
柔軟でコンテクストを読んだ返答をできるが,ときには理解に欠けていたり,怠けた返答を見せることがある
検索ベースのモデルは
人の返答の集合から実際の返答を選ぶため,返答の集合は有限集合であり,コンテクストと相関がないことがある.
ただし,表面上のレベルでは,首尾一貫した返答することも多い
以下は,オープンドメイン型対話システムにおける,難しさとホットなトピックをまとめる
- Context Awareness
- 対話コンテクストは会話のトピックを決定したり,ユーザの目標を決定したりと重要
- コンテクストを解釈した対話エージェントは,現メッセージだけではなく,対話履歴からももとにして返答する
- 生成モデルも検索ベースも,どちらも対話コンテクストモデリングに依存する
- いくつかのモデルではAttentionが使用されているらしい
- 構造化されたAttentionを用いることでコンテクストを読み取れる?
- 対話をリライトする問題があるらしい
- 複数のメッセージから単一のメッセージに変換する目標
- ここではコンテクストを理解させることが重要
- Response Coherence
- 首尾一貫した返答は,良い生成器としての一つのクオリティ
- 対話の中で,論理的で首尾一貫しているか?という指標
- 生成モデルにおいてホットなトピックとなっている(検索ベースはすでに人の返答をりようするのでもともと一貫性はあるという主張)
- 一貫性のない文の順序を見つけるタスクを解くことで,返答の一貫性を改善した事例もあり
- Response Diversity
- 人が多用するような表現は訓練コーパスにも多く含まれ,それらばかりを返答してしまうことが問題となりうる
- かつては条件付き確率において,尤度関数を解くことで尤もらしい返答をもとめていた.
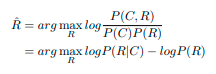
- この手法では,返答の精度の安全性と適切さはトレードオフになっていた?
- ビームサーチを提案されたことも
-
- Speaker Consistency and Personality-based Response
- システムは,訓練コーパスからサンプリングされた分布に対して学習
- 対話者の趣味といった一貫性のないものに対する返答は...
- 対話者の役割を理解し,その個人に合わせた返答が必要になる
- 1ステージではなく,3ステージで個人的な嗜好に対応した事例がある
- システムは,訓練コーパスからサンプリングされた分布に対して学習
- Empathetic Response
- 同情する対話システムは,ユーザの感情の変化や感情に伴った適切な返答をする
- 雑談チャットについて,このトピックは重要
- CortanaやAlexaなどの製品にもモジュールが含まれている
- CoBERTのモデルなど
- 感情対話システムのデータセットはとぼしいが,新たなデータセットとベンチマークが提供されたらしい
- Conversation Topics
- トピックや目的は,会話に参加した人と会話を続けるための重要な役割を果たす
- トピックを理解させることが重要
- Knowledge-Grounded System
- 人は,会話のコンテクストと経験や記憶といったものとを関連付けて,返答をする(機会には難しい)
- 生成モデルは,単なる機械翻訳よりも複雑
- より自由度が高く,制約が曖昧なため
- 故に,雑談チャットは,外部から得られる常識と結びつけて,seq2seqなモデルによって生成する
- メモリーネットワークなどで,知識をグラウンディングする手法
- 知識グラフは外部の情報をソースにするものもある.
- graph attentionを用いて,常識をグラフベースで学習する手法も
- 主な考え方は,外部の知識グラフを使って,会話の論理の流れをモデリングする指標の一部として扱う
- Interactive Training
- 別名;human-in-loop training
- アノテーションされたデータセットは限られている
- すべての状況をカバーすることは不可能
- ユーザとの対話の中で,システムを改善する
- 強化学習における逐次学習を提案
- 対話相手と話して,その相手からフィードバックを得る
- 教師あり学習をした後,Interactive Trainingによってファインチューニングする
- Visual Dialogue

- Visual Q & Aなど
- 画像あり対話システムのほか,映像あり対話システムも面白いトピックだが難題でもある
- 特徴量抽出の複雑さも増す
- visual dialogueのアノテーションは重労働であり,データセットに乏しいので,現在はデータの不十分さに悩まされている
-
評価のアプローチ
評価の仕方も重要なパートとなっている
- タスク指向型対話システムにおける評価
- BLEUスコアを用いて,システムの返答と人の返答を比べるなど
- Task Completion Rate
- すべてのタスクの試行に対して,いくつのイベントが成功したかの割合
- Task Completion Cost
- タスクをこなすのに使われたリソース
- 解決までの時間が重視されるタスクにおいて用いられる
- なるべく短いターン数で完遂するのが良しとされる
- Human-based Evaluation
- ユーザの対話とユーザの満足度のスコアを提供
- 方法はふたつ
- クラウドソーシングで労働を雇う
- 実際にローンチしてからユーザのフィードバックで評価する
- オープンドメイン型対話システムにおける評価
- 明確なメトリックはない
- 長らくHuman Evaluationを使ってきた
- Word-overlap Metrics
- 生成された系列と実際の系列の近さを計算する
- 機械翻訳や要約タスクにおいて用いられる
- n-gramのものとして
- BLEU
- ROUGE
- METEOR(BLUEの改良版)
- Neural Metrics
- ニューラルモデルによって計算させる
- RNNやCNN,GANの識別器を使うなどして,ターンレベルの特徴量抽出を行うなど
- 今もホットなトピックになっている
データセット
タスク指向型対話システム
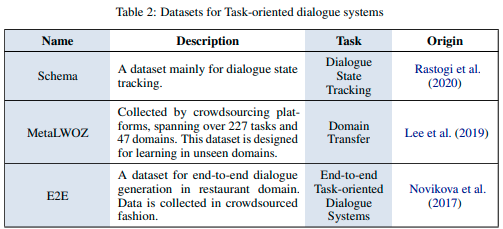
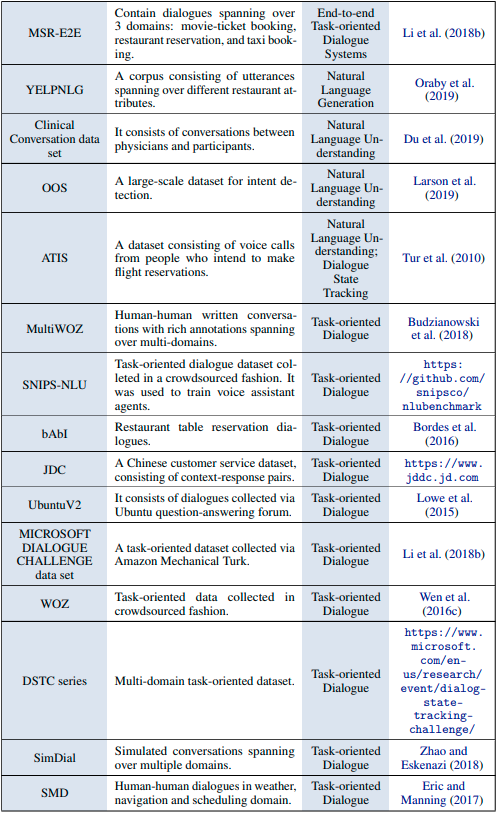
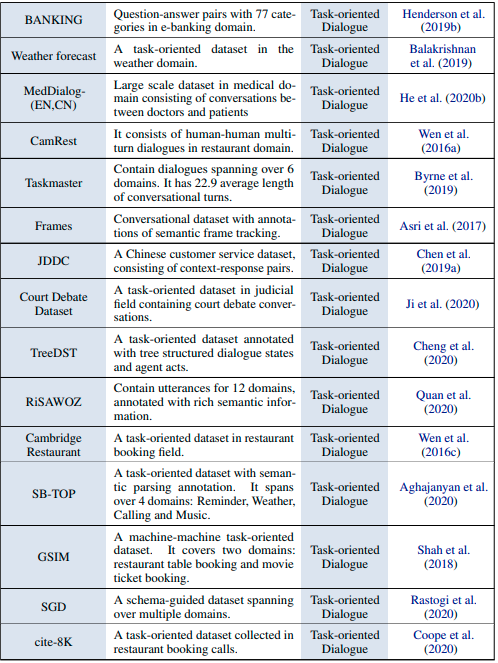
オープンドメイン型対話システム
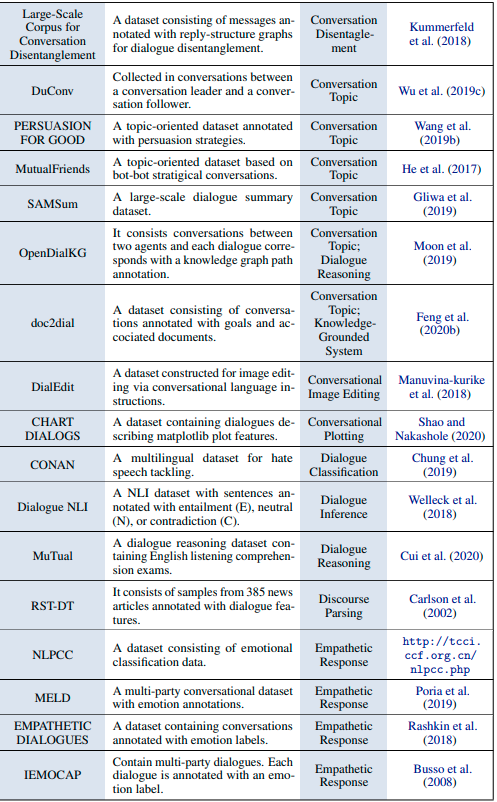
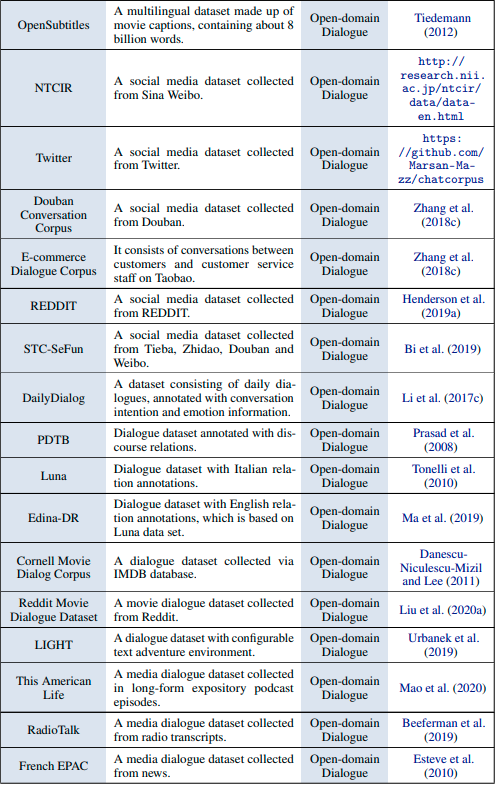
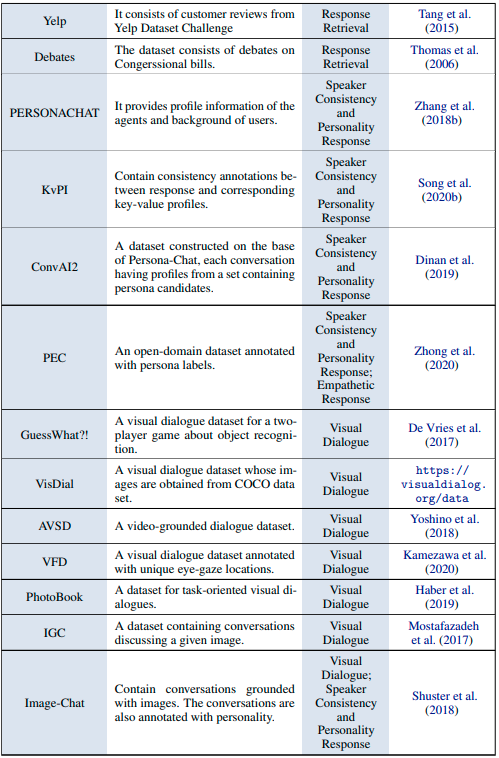
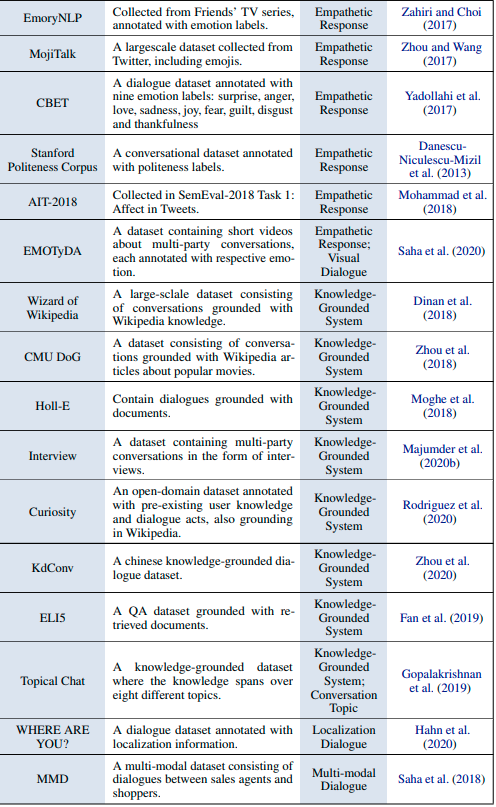
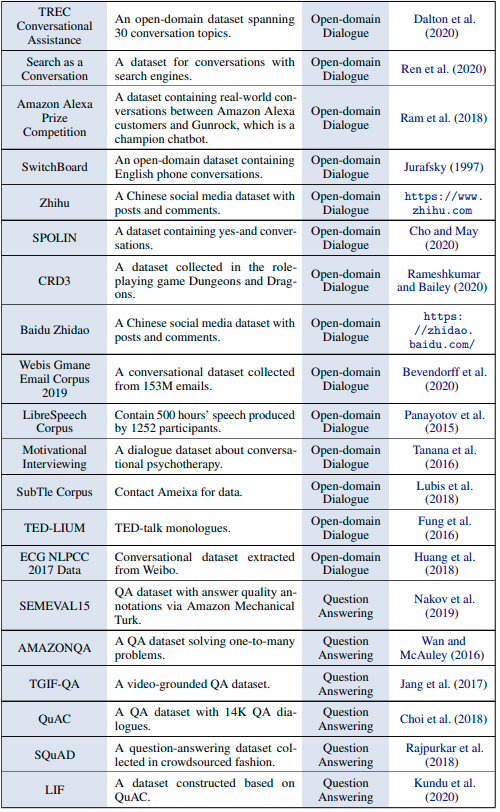
結論とトレンド
ココ最近のトレンド
- Mutlimodal dialogue systems
- 異なるモダリティを組み合わせる
- Multitask dialogue systems
- タスク指向型と知識グラウンディングさせたオープンドメイン型を組み合わせて,一つのフレームワークまたはシングルモデルとして完結させる
- Corpus exploration on Internet
- real-timeなコーパスをインターネットから取り出せるようになれば,期待がもてる
- 研究に値するのでは?
- User modeling
- 生成と評価の双方でホットなトピック
- Dialogue generation with a long-term goal
- 日常的な雑談は特に目的はない
- しかし,会話が意図的にある特定の目的に向かうときは,ほんの少しでも状況があるはず
- 現在のオープンドメイン型は,長期的な目的を除いてモデリングされがち
- 十分な知性を備えていない