本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Prompt-Tuning による個性を持った対話システムの構築
研究会: NLP
年度: 2022
キーワード: dialogue system, persona, Prompt-Tuning
URL: https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/B2-1.pdf
データセット: PERSONA-CHAT, DailyDialog
概要
与えられたキャラクター設定(ペルソナ)を考慮した応答生成をする雑談対話システムの構築
一貫した発話をしない対話システムは魅力的ではない
→ 一貫性を持たせるためペルソナに着目
Prompt-Tuningを行うことで,Fine-Tuningに比べて学習時間と計算資源を削減しつつ,より自然で個性を持ったシステムの構築
提案手法
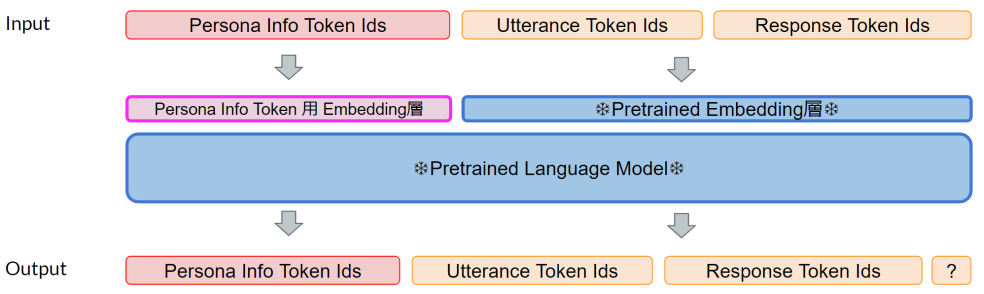
ペルソナ情報を埋め込むトークン(Persona Info Token)用のEmbedding層を追加したTransformerモデルを提案
この新たに追加したEmbedding層のパラメータを更新する
新規性
事前学習済みモデルのパラメータを更新しないPrompt-Tuningによって学習
→ 学習に要する時間と計算資源の削減が可能
数百個の対話ペアからなる小規模なデータセットであっても,個性を持ったシステムの構築が可能
実験
データセット:Persona-Chat/DailyDialog
1往復の2初話ずつに分割→これを対話ペア
使用するペルソナ:Persona-chatにおける対話ペア数の多い上位3種類のペルソナのみ
ペルソナとは無関係な対話ペアとしてDailyDialogを使用
→ TopicがRelationshipの対話ペアを使用
中でも発話と応答の両方の長さが50文字以下の対話ペアを一定の比率で学習用データセットに混ぜる
→ なぜ?:短い発話やペルソナと無関係な一般的な発話おデータセットに取り込む
ペルソナ文を与える際,長さ<200の時は,200になるまでペルソナぶんを繰り返し並べる
生成の戦略にはGreedy searchを採用
まとめ
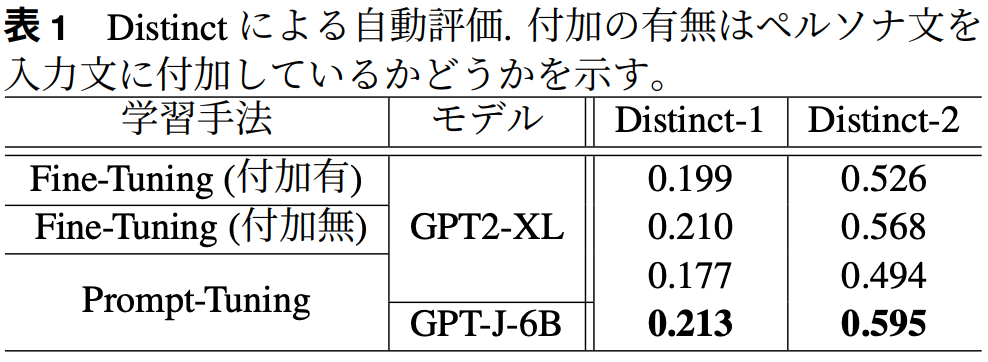
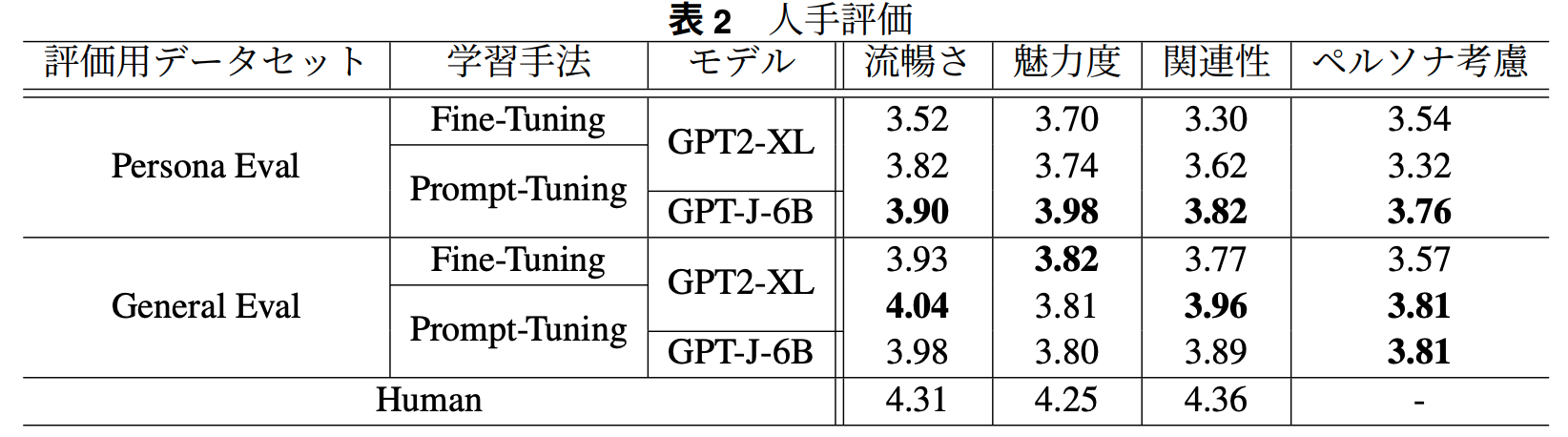
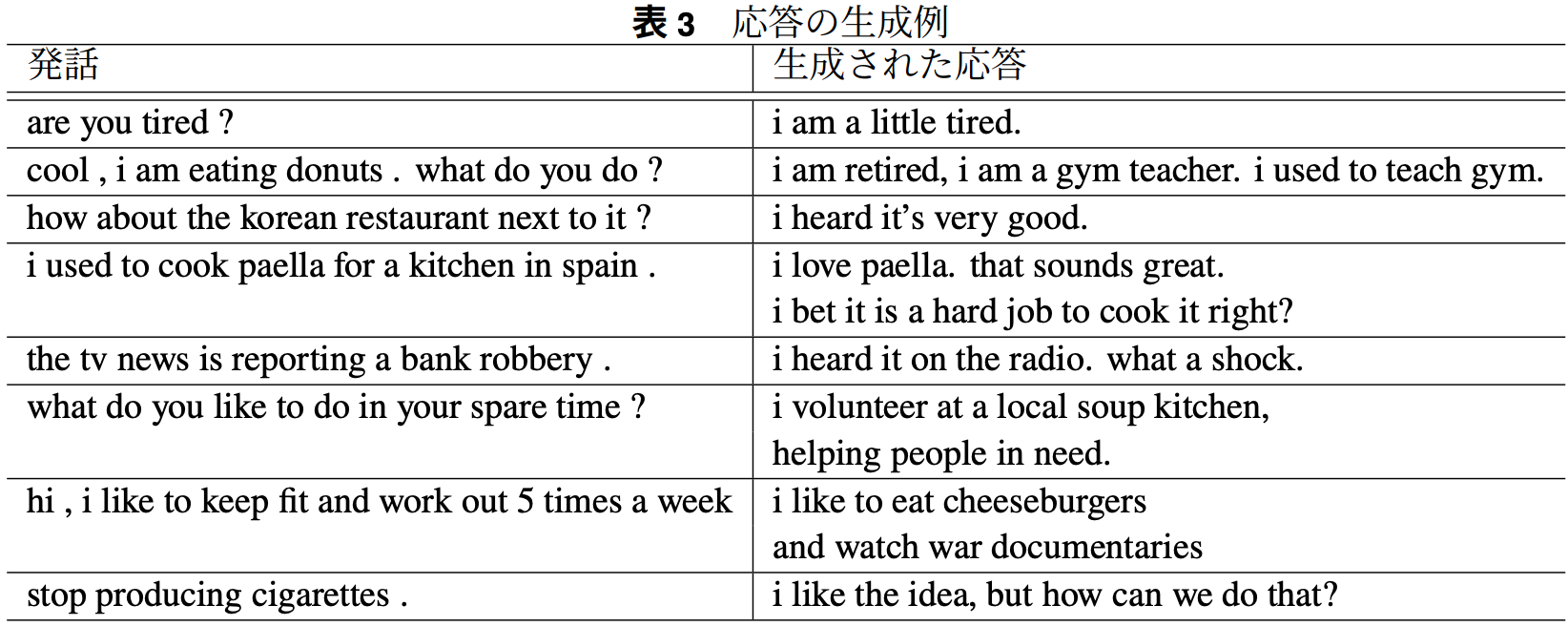

自動評価時:distinct-{1, 2}
GPT-J-6BをPrompt-Tuningしたモデルが最も多様性のある生成
Fine-Tuningの時は入力にペルソナを孵化しない方が良い性能
人手評価時
全ての項目においてGPT-J-6BをPrompt-Tuningしたモデルの評価が高い
その他(なぜ通ったか?等)
LINEとの共同研究
AI-Bridging cloudを用いてA100(40GB)を使用した実験