本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Prediction of Shared Laughter for Human-Robot Dialogue
研究会: ICMI
年度: 2020
キーワード: laughter, shared laughter
URL: http://sap.ist.i.kyoto-u.ac.jp/lab/bib/intl/LAL-ICMI20.pdf
DOI: https://doi.org/10.1145/3395035.3425265
データセット:
提案手法
会話ロボットがshared laughterを自動生成することを目的にする
Shared Laughter Model
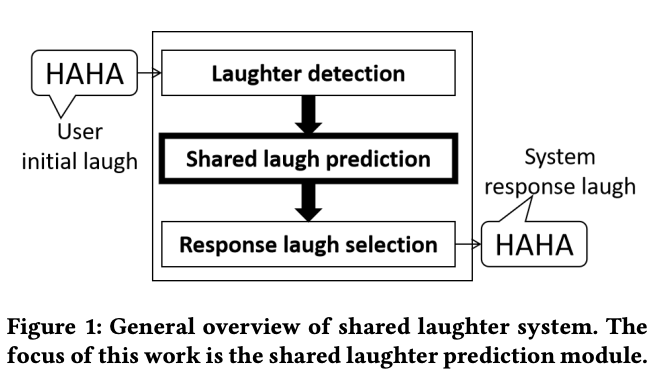
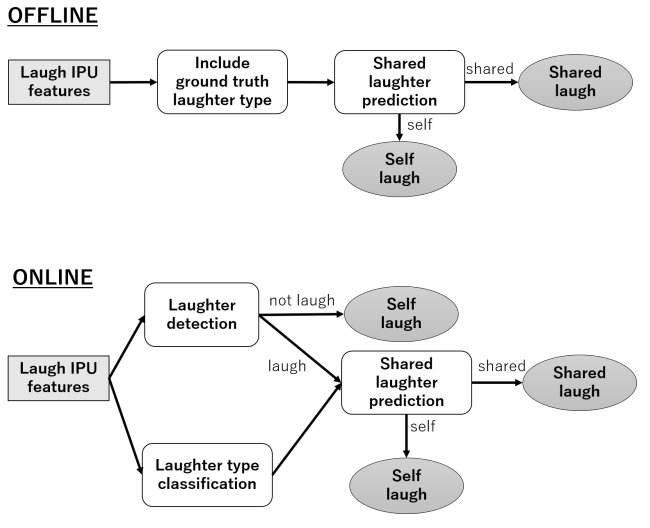
ユーザの最初の笑いを検知して,システムが笑うモデル
3種類のモジュールが存在する
- ユーザの最初の笑いを検出
- shared laughterを生成するかどうかを決定
- どのタイプの笑いをするべきか決定
Data Collection and Analysis
収集方法:ERICA
teleoperateしたのは女性
対象:61人の男性
シナリオ:speed dating
好きな趣味,好きなこと,嫌いなことに関してカジュアルなチャット
アノテーション:
2種類のタイプに笑いを分けた
- isolated laugh 1. 笑い単体で起こる笑い
- speech laugh
1. 話しながら起こる笑い
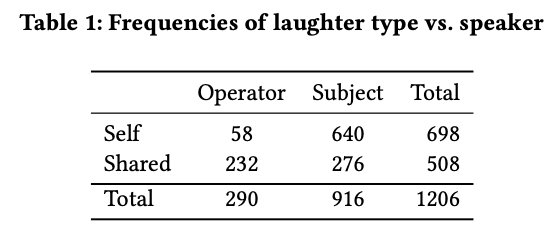
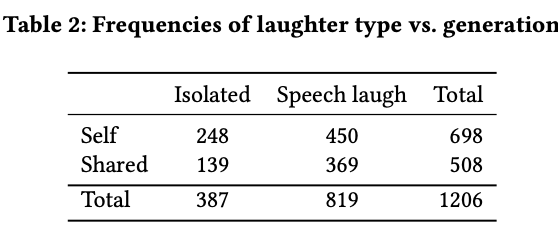
集まったデータの中で,1206件のinitial laughが確認
698件がself laughで508件がshared laugh
Model Creation
特徴量2種類:
Audio-based features
40のacoustic メルフィルタバンクの平均と標準偏差
Prosodic features
全IPUにまたがるピッチとパワーの値を使った合計で14つの以下の指標
平均/中央値/標準偏差/最大値/最小値/範囲
モデル:
LR/SVM
データサンプルが小さかったからか,deep learningの手法は弱かった
新規性
ユーザに合わせて毎回笑いを生成するのではなく,適切なタイミングでshared laughterを自動生成することをロボットに持たせたいという目的をもった研究
評価方法
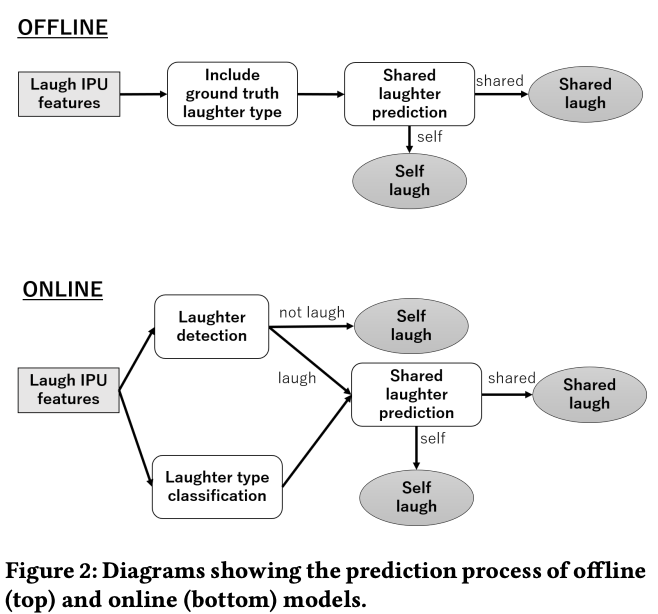
オフラインとオンラインの二つのタイプで評価
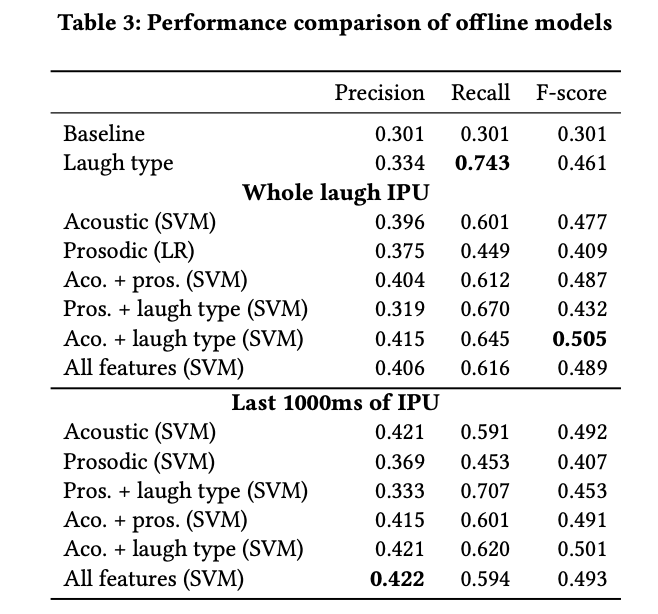
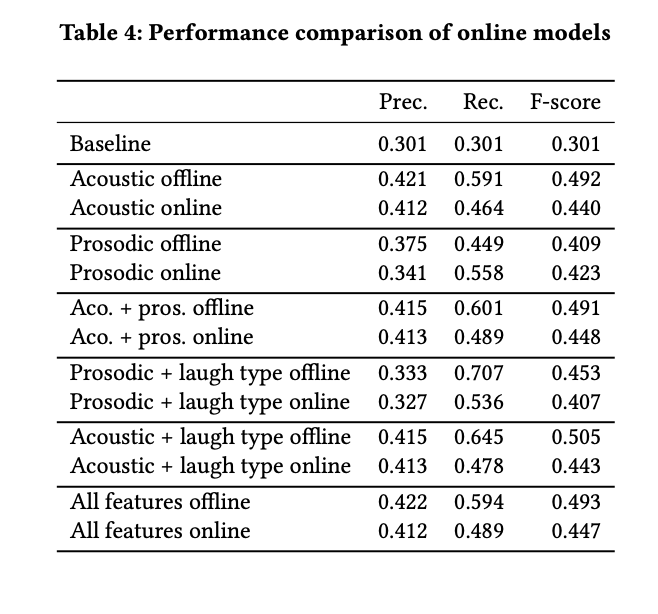
特徴量としてlaughter typeを加えることでrecallが改善する傾向
負に歪んだピッチの分布の時は笑いがシェアされがちで笑いが長く続きがち
laughter detectionとlaugh type classificationのエラーによってパフォーマンスが落ちることは明らかだが,それでもベースラインをoutperform
最もよかったonline modelはacousticとprosodicの特徴量を両方使ったもの
何がすごかった?
prosodicの分析からわかったことが,initial laughのacousiticsはresponse laughを呼び起こすいくつかの特徴があること
まだ改善の余地はあるものの,acousticとprosodicの特徴量の両方を使うことはパフォーマンスの改善に役立った
shared laughterのタイミングについてはかけた研究である
今後の課題である
次に読みたい論文
引用
@inproceedings{10.1145/3395035.3425265, author = {Lala, Divesh and Inoue, Koji and Kawahara, Tatsuya}, title = {Prediction of Shared Laughter for Human-Robot Dialogue}, year = {2020}, isbn = {9781450380027}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3395035.3425265}, doi = {10.1145/3395035.3425265}, abstract = {Shared laughter is a phenomenon in face-to-face human dialogue which increases engagement and rapport, and so should be considered for conversation robots and agents. Our aim is to create a model of shared laughter generation for conversational robots. As part of this system, we train models which predict if shared laughter will occur, given that the user has laughed. Models trained using combinations of acoustic, prosodic features and laughter type were compared with online versions considered to better quantify their performance in a real system. We find that these models perform better than the random chance, with the multimodal combination of acoustic and prosodic features performing the best.}, booktitle = {Companion Publication of the 2020 International Conference on Multimodal Interaction}, pages = {62–66}, numpages = {5}, keywords = {shared laughter, machine learning, human-robot dialogue, conversation}, location = {Virtual Event, Netherlands}, series = {ICMI '20 Companion} }