本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Multimodal Humor Dataset: Predicting Laughter tracks for Sitcoms
研究会: WACV
年度: 2021
キーワード: humor detection, multi-modal
DOI: http://dx.doi.org/10.1109/WACV48630.2021.00062
データセット: MHD (Multimodal Humor Dataset)
概要
マルチモダールなユーモアデータセット(MHD; Multimodal Humor Dataset)(The Big Bang Theoryを使用)を構築
海外のSitcoms (Situation comedies) では笑い声がドラマ内に含まれている
→ sitcomsは定期的に作成されていて,この笑い声を自動で追加するタスクがクリティカルなタスク
→ 笑い声の自動挿入のタスクを自動化することが狙い
構築されたデータセットを用いて,マルチモーダルを利用したAttentionベースのモデルを構
→SoTA & データセット分析
提案手法

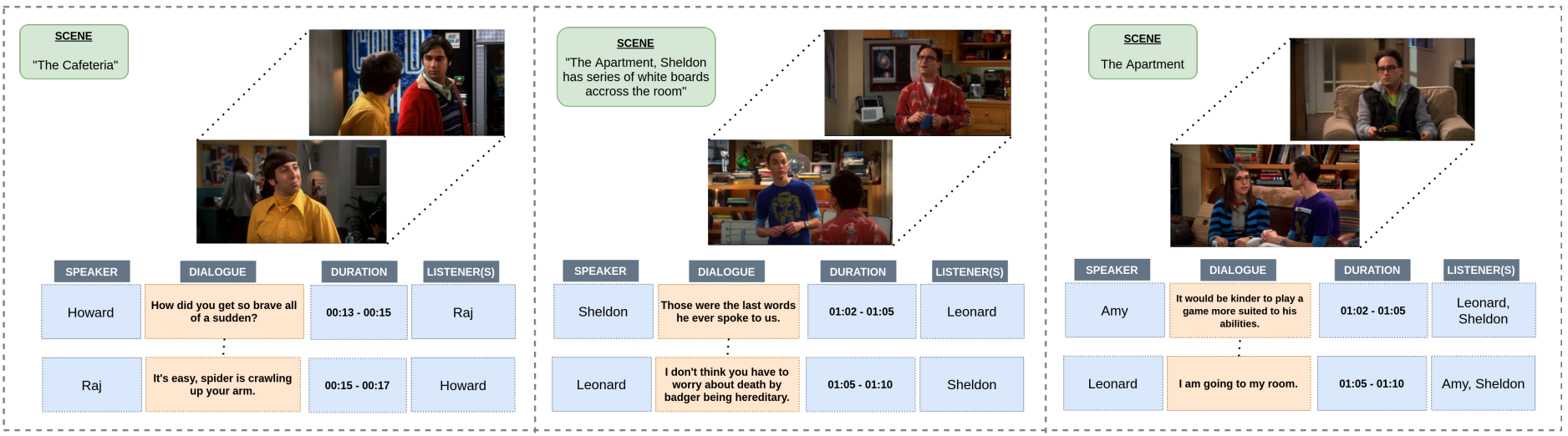
データセットのこと
対話のチャンクに対してlaughter tracksを使用してラベルを付与
笑い声をアノテーションすることがは間接的に人手でのアノテーションと同じになるという過程
→ 笑い声の起こる直前の発話の集合をユーモアとしてラベル付け
Attributes
- Scene
- Speaker
- Recipients
- Participants
- Dialogue Turns
- Dialogue Start/End time
- Humor Start/End time 対話のチャンクに複数のlaughter tracksがある場合,最後のみ適用
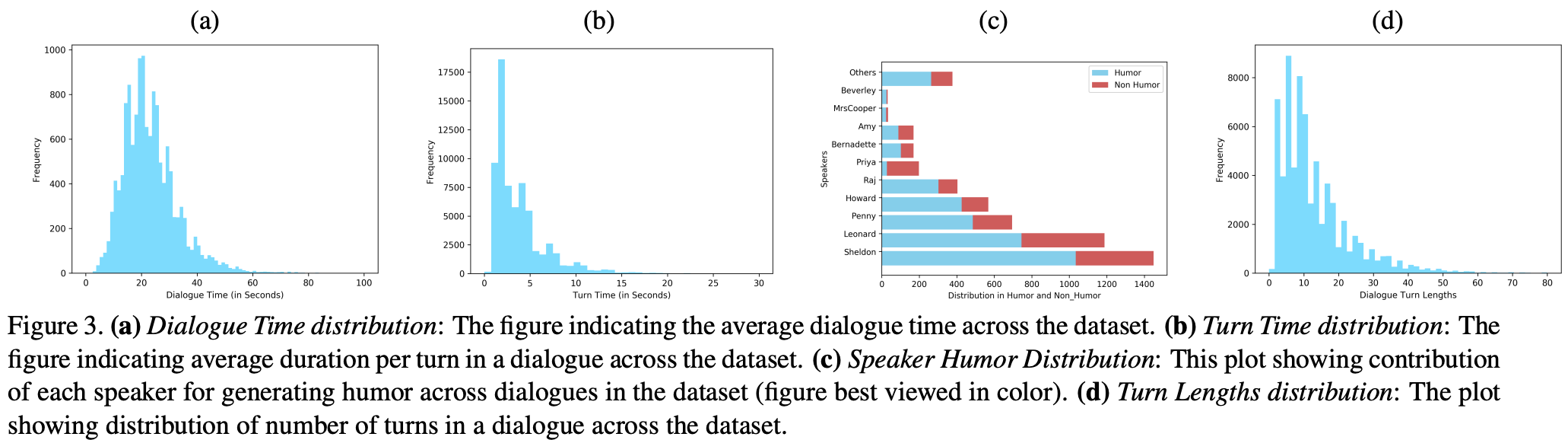
データ分析の結果はFig 3.を参照のこと
モデルのこと
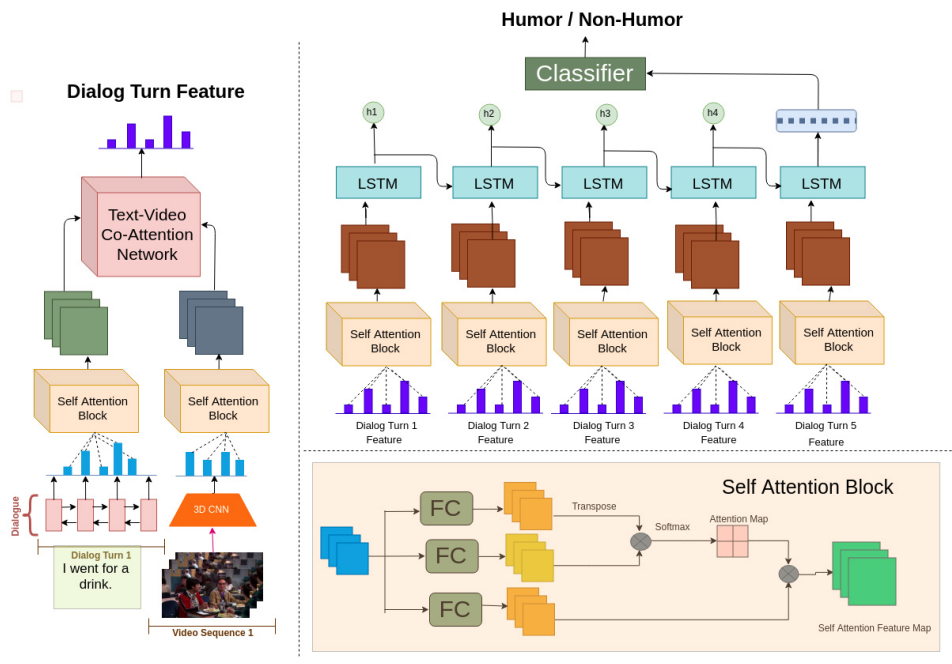
新規性
- 手動でアノテーションされたマルチモーダルな大規模ユーモアデータセットを構築
- これまでのSoTA手法を実験しつつ,multimodal self attention based modelを提案
- 提案手法の汎化性能を検証
実験
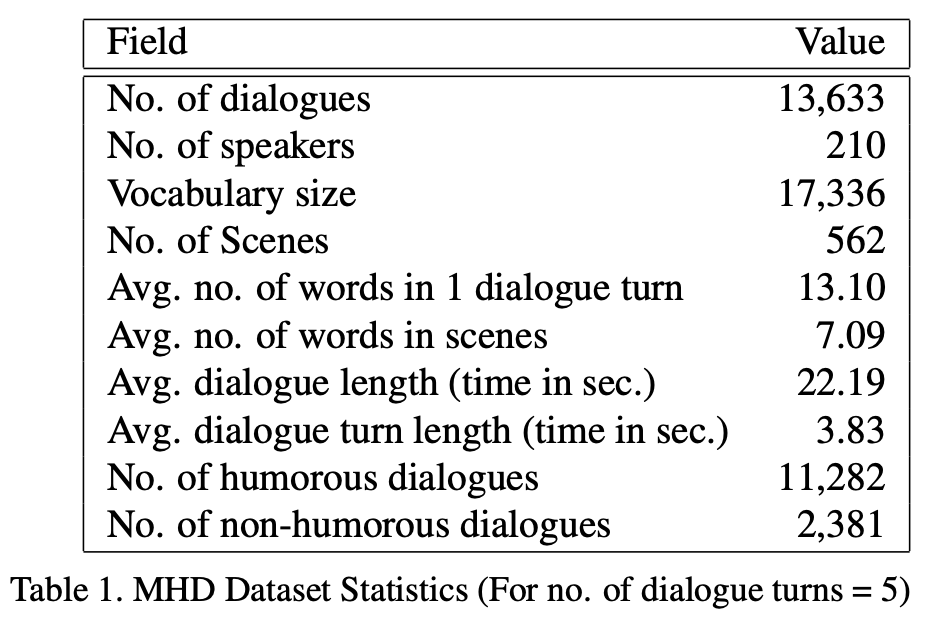
5 turns / dialogueとする
humor : non-humor = 1 : 2としてサンプリング
humorのラベルが85%と高く,かなり不均衡のため
実験モデル
{Attention, Fusion, Sequential} with {only Text, only Video, both of them}
評価指標:
Accuracy, ROC, F1
まとめ

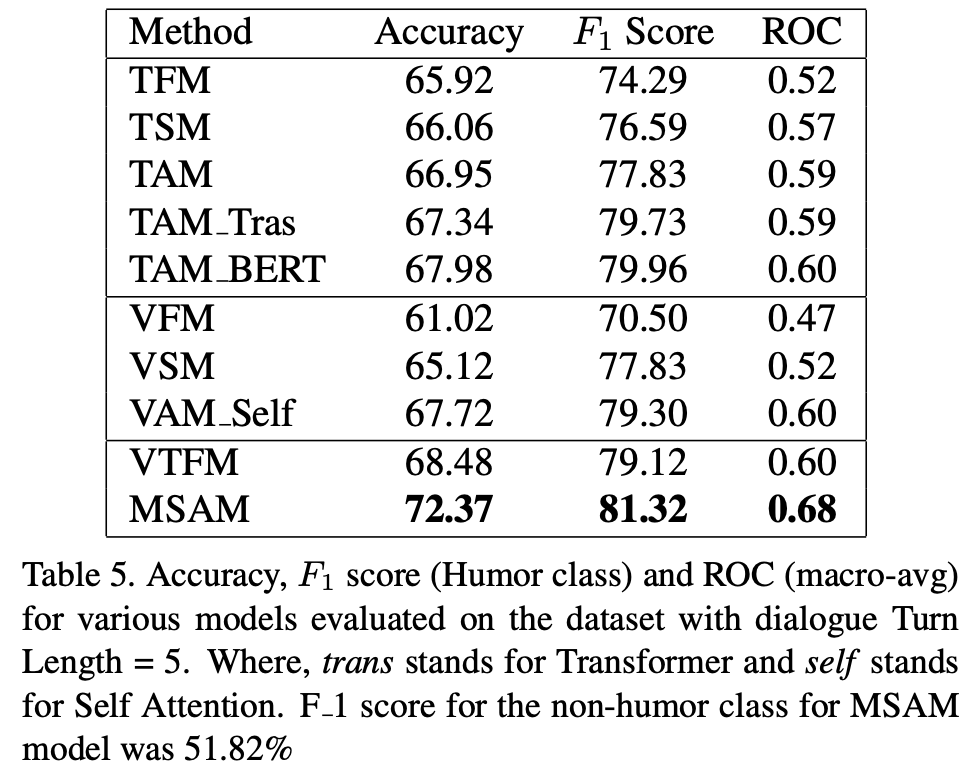
提案手法のMSAMが強い
表情や動作のようなvisual特徴量がユーモアの合図になっていることがある
→ visual特徴量を使うことが有効である
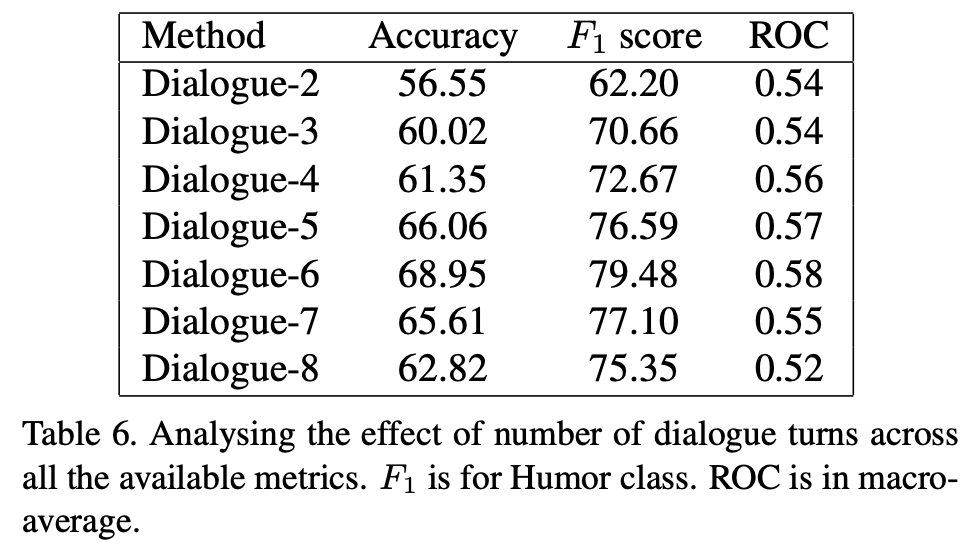
@Table 6.より,dialogueのターン数を長くするとよりcontextualにできるが,長くしすぎても精度が落ちている
→ dialogue 5, 6がピークになっている→ ゆえにturn数を5として本研究は進められている
Discussion
- 良いモデルはテキストと視覚的な特徴量の重みづけの仕方を正しく考慮しなければならない
- 失敗例への対策
- よりlong tailなユーモアにロバストにならなければいけない
- 例)Sheldonは滅多にブランケットを羽織らない→羽織った時面白くなる
- 知識ベースの弱さへの改善
- sitcomsは皮肉での笑いが多い(知識がないと伝わらないことがある
- よりlong tailなユーモアにロバストにならなければいけない
その他(なぜ通ったか?等)
次読みたい論文
引用
@INPROCEEDINGS{9423266, author={Patro, Badri N. and Lunayach, Mayank and Srivastava, Deepankar and Sarvesh, Sarvesh and Singh, Hunar and Namboodiri, Vinay P.}, booktitle={2021 IEEE Winter Conference on Applications of Computer Vision (WACV)}, title={Multimodal Humor Dataset: Predicting Laughter tracks for Sitcoms}, year={2021}, volume={}, number={}, pages={576-585}, doi={10.1109/WACV48630.2021.00062}}