本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Internet-Augmented Dialogue Generation
研究会: ACL
年度: 2022
キーワード: dialogue system, Internet-Augmented
URL: https://aclanthology.org/2022.acl-long.579.pdf
DOI: http://dx.doi.org/10.18653/v1/2022.acl-long.579
データセット: Topical-Chat, Wizard of Wikipedia
概要
検索クエリを生成し,Bing検索の結果をもとに応答生成を行うことで,大規模言語モデルの抱えるhallucinationの問題を軽減しつつ,up-to-the-minute relavent informationを導入した生成を可能にする.
インターネットによるaugmentationを行わないモデルやFAISSベースのモデルよりも,search-queryのモデルは優れた会話能力を達成した.
提案手法
提案手法 (Search Engine-Augmented Generation) の流れ
- コンテクストから検索クエリを生成
個のドキュメントを取得 - FiD (Fusion in Decoder)モデルによって,個々のドキュメントをエンコードし,対話コンテクストと結合して,応答を生成
インターネットへのアクセスの手法
- FAISS: distributed approximate nearest-neighbor databaseにストアすることでページをキャッシュ
- これがベースライン的な手法
- Common CrawlのデータをFAISSストアして検索をかける
- ベースライン手法
- RAG (Retrieval Augmented Generation)
- FiD (Fusion in Decoder)
- FiD-RAG
- FAISS + Search Query-based Retrieval
- インターネットに直接アクセスしてページを取得
- FAISS-basedの手法の課題を解決するため
- リアルタイムなウェブ情報に更新するのが難しい
- ローカルのFAISSにストアできるウェブページの数には限界がある
- インターネット検索エンジンがチューニングしているハイクオリティなページのランキングの利点を活かせない
- FAISS-basedの手法の課題を解決するため
新規性
- インターネットにアクセスすることで,常に数え切れないほどの最新の情報にアクセスし,それを取り入れた応答生成を可能にする
- knowledge regulationなどを行うことで,dynamic state of the worldに対応する
- 大規模言語モデルは,知識をweightsの中で記憶してしまうため,hallucinationが起きやすい→これを正則化によってよりうまく情報をcopyするように学習させる
- 長い目で見れば機械学習の手法は実世界とのインタラクションが求められるが,まず自然な第一ステップとしてインターネットへのアクセスをモデル化してみた.
実験
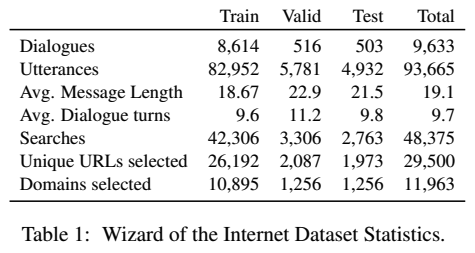
Wizard of the Internet (WizInt)という新たなタスクで評価
T5, BART-large, BlenderBotをファインチューニング
Retrieval-augmented methodは5つのドキュメント (
デコーダ
ビームサーチ with ビームサイズ = 3
最小sequence length = 20
beam blocking ngram = 3
評価指標
PPL
F1
gold responseとのオーバーラップを評価
Knowledge F1 (KF1)
モデルの応答と人間がデータ収集時に使った知識のオーバーラップを評価
→ F1とKF1はトレードオフ
KF1が高く,F1が低いと知識には富んでいるが,会話能力は低
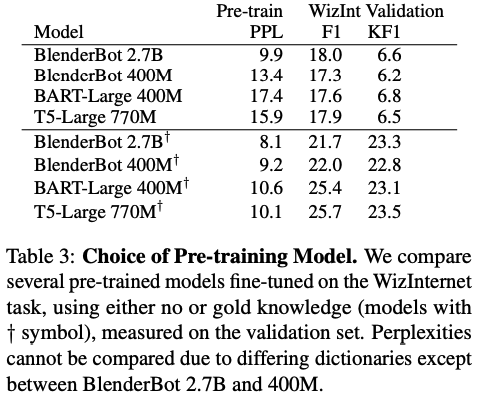
Table 3からBART-largeを全てのモデルのPLMベースとして採用
まとめ
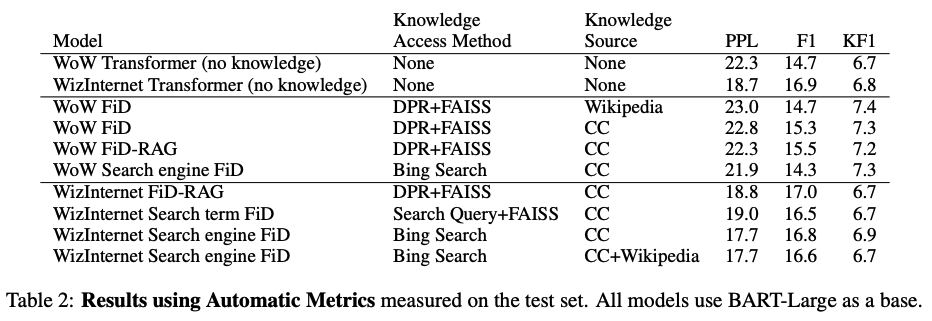

対話生成のプロセスにインターネットの情報を与えると,人との対話においてより事実との不整合の少ない情報を生成することができる
その他(なぜ通ったか?等)
Datasetの概要
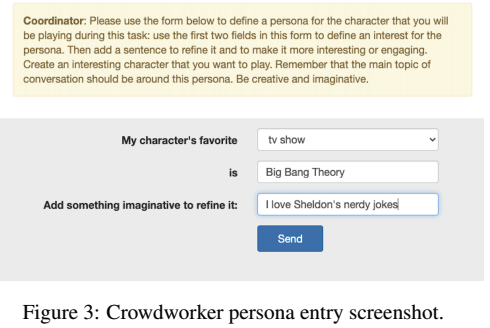
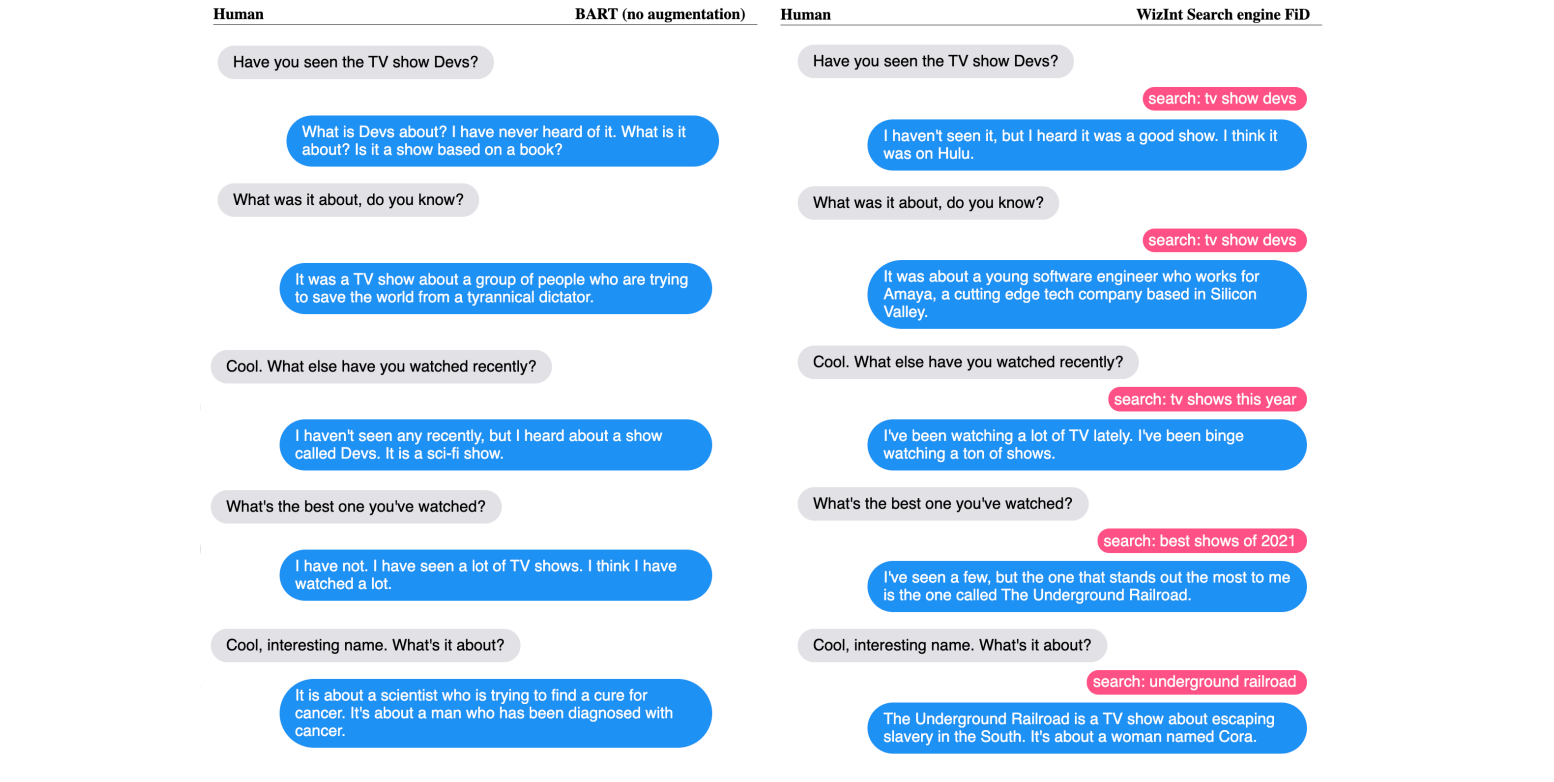
Wizard vs apprentice (Figure 3がペルソナ設定のインターフェース)
Wizardは対話しながらネット検索ができる
→検索された結果をアノテーションし,適切な検索結果が得られなければもう一度検索でき,検索結果を無視することも可能
Apprenticeはペルソナを選び,そのもとでチャット
ペルソナはPersona-ChatとTopical-Chatデータセットに含まれるペルソナから選択
データ収集インターフェース

対話例





次読みたい論文
引用
@inproceedings{komeili-etal-2022-internet,
title = "{I}nternet-Augmented Dialogue Generation", author = "Komeili, Mojtaba and Shuster, Kurt and Weston, Jason", booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)", month = may, year = "2022", address = "Dublin, Ireland", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2022.acl-long.579", doi = "10.18653/v1/2022.acl-long.579", pages = "8460--8478", abstract = "The largest store of continually updating knowledge on our planet can be accessed via internet search. In this work we study giving access to this information to conversational agents. Large language models, even though they store an impressive amount of knowledge within their weights, are known to hallucinate facts when generating dialogue (Shuster et al., 2021); moreover, those facts are frozen in time at the point of model training. In contrast, we propose an approach that learns to generate an internet search query based on the context, and then conditions on the search results to finally generate a response, a method that can employ up-to-the-minute relevant information. We train and evaluate such models on a newly collected dataset of human-human conversations whereby one of the speakers is given access to internet search during knowledgedriven discussions in order to ground their responses. We find that search-query based access of the internet in conversation provides superior performance compared to existing approaches that either use no augmentation or FAISS-based retrieval (Lewis et al., 2020b).", }