本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Highway Transformer: Self-Gating Enhanced Self-Attentive Networks
研究会: ACL
年度: 2020
キーワード: transformer, Highway Transformer, Gating Mechanism, Self-Dependency-Units (SDU)
URL: https://aclanthology.org/2020.acl-main.616.pdf
DOI: http://dx.doi.org/10.18653/v1/2020.acl-main.616
コード: https://github.com/cyk1337/Highway-Transformer
データセット: Penn Tree Bank (PTB), enwik8
概要
LSTM-styleなSDUを提案
ゲートとしてSDUをTransformer内部に適用することにより,ハイパラをチューニングすることなく,Transformerの浅い層において,内在的な意味の重要性を捉え,より早い収束を可能に
提案手法
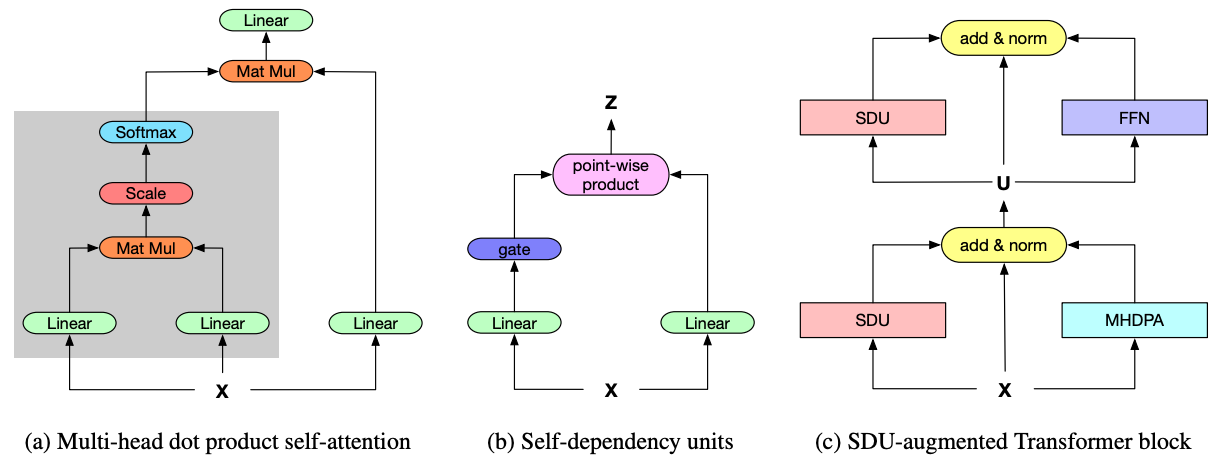
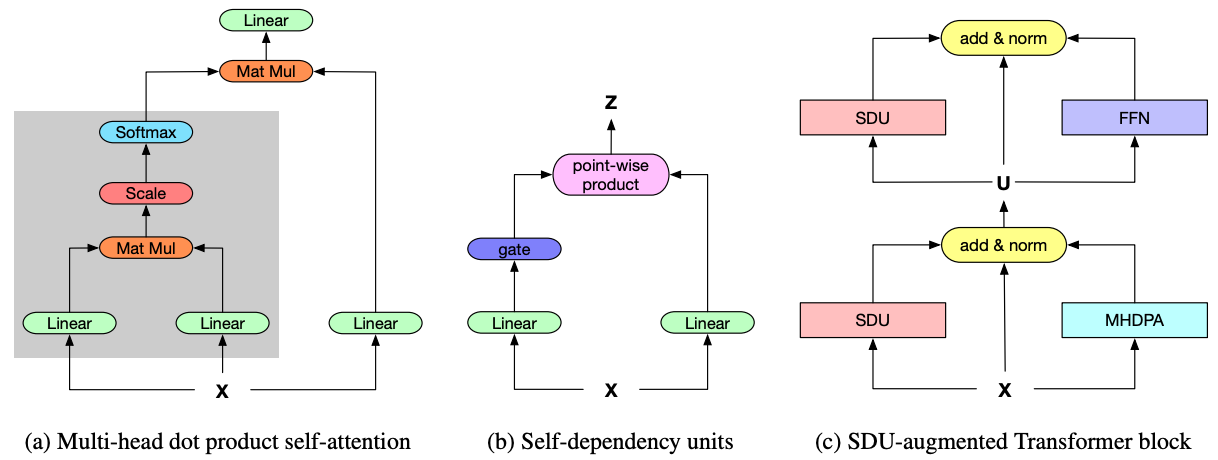
Self-Dependency Units (SDU)
sigmoid gatesを導入する
筆者らの認識
tanhはupdate gateとして作用し,重要度の幅を-1 to 1に制限
sigmoidはLSTMのinput gateと似ていて,feature-wise levelでどれくらいの情報を残すか決定
Pseudo-highway Connection
residual connectionされたgating-modified encodingsでMulti Head Dot Product Attention (MHDPA)の分散表現を豊かにするため,新たな計算グラフの枝を追加し,SDUとIdentityとMHDPAをpost LNを使用してresidual connectionする
新規性
本来,人にとって,読み物をよりよく理解するためには,global contextだけではなく,ここの単語の意味も必要
→ Self-gatingなアプローチを提案
- Transformerにおける浅い層において,trainingとvalidationでハイパラチューニングすることなく,より高速な収束を達成
- Transformerでの低レイヤーにおいて,local-range encodingにフォーカスした層を実現
- Self-gating mechanismは,R-TransformerやTransformer-XLのコンポーネントとしてRNN-likeなメカニズムを補完
実験
SDUを導入し,PTBデータセットにおけるSDUの効果を検証
sigmoidとtanhを実験
まとめ
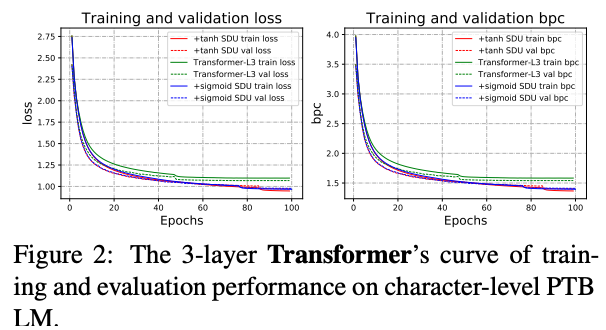
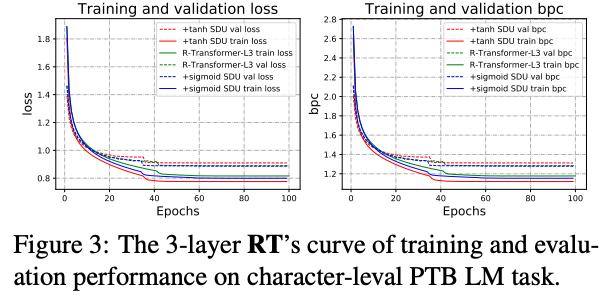
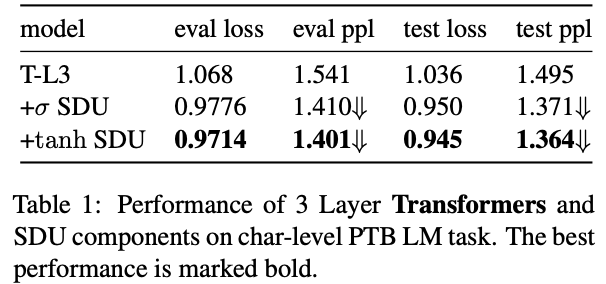
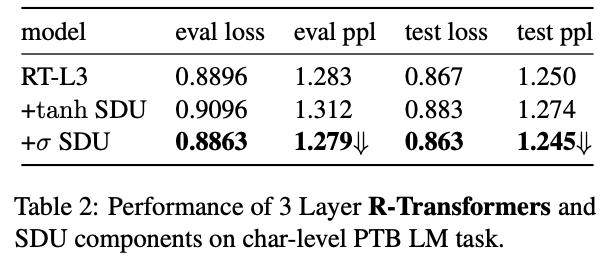
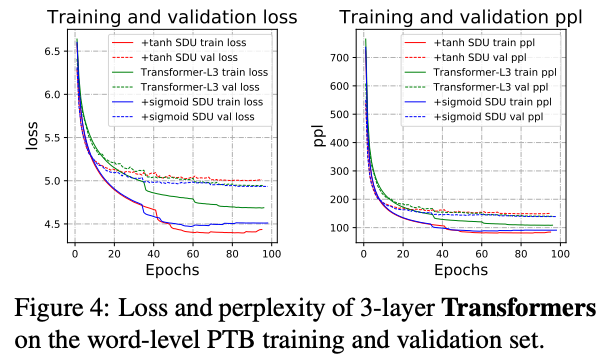
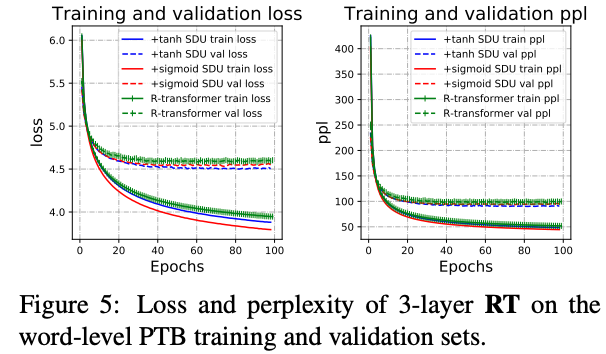
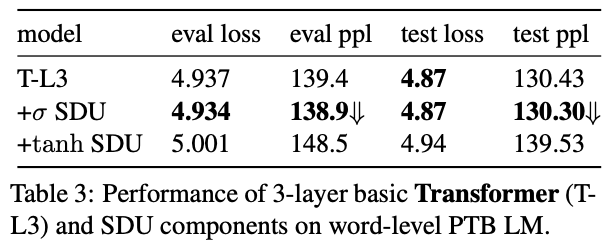
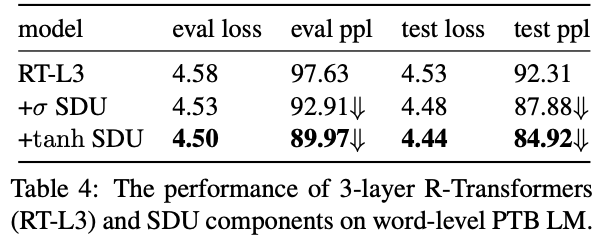
sigmoidによるSDUが安定しているが,データとタスクによってはtanhの方がoutperformすることがある
いずれのactivationを使っても収束は早い
enwik8による大規模データでの追実験において,提案手法が浅いレイヤーには寄与することが確かめられた
SDUで計算量が増えるが,そこまで差はなかった
その他(なぜ通ったか?等)
次読みたい論文
引用
@inproceedings{chai-etal-2020-highway, title = "Highway Transformer: Self-Gating Enhanced Self-Attentive Networks", author = "Chai, Yekun and Jin, Shuo and Hou, Xinwen", booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics", month = jul, year = "2020", address = "Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2020.acl-main.616", doi = "10.18653/v1/2020.acl-main.616", pages = "6887--6900", abstract = "Self-attention mechanisms have made striking state-of-the-art (SOTA) progress in various sequence learning tasks, standing on the multi-headed dot product attention by attending to all the global contexts at different locations. Through a pseudo information highway, we introduce a gated component self-dependency units (SDU) that incorporates LSTM-styled gating units to replenish internal semantic importance within the multi-dimensional latent space of individual representations. The subsidiary content-based SDU gates allow for the information flow of modulated latent embeddings through skipped connections, leading to a clear margin of convergence speed with gradient descent algorithms. We may unveil the role of gating mechanism to aid in the context-based Transformer modules, with hypothesizing that SDU gates, especially on shallow layers, could push it faster to step towards suboptimal points during the optimization process.", }