本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Editing Models with Task Arithmetic
研究会: ICLR
年度: 2023
キーワード: Weight Interpolation, Model Patching, Merging Models, Model Editing, Transfer Learning
URL: https://arxiv.org/pdf/2212.04089.pdf
DOI: https://doi.org/10.48550/arXiv.2212.04089
コード: https://github.com/mlfoundations/task_vectors
データセット: SVHN, GLUE, WikiText-2, DTD, WikiText-103, C4, EuroSAT, Sketch, RESISC45, Cars, GTSRB, MNIST, SUN397, ImageNet, CivilComments, Yelp
概要
Task vectorに基づいたニューラルネットワークの編集の新たなパラダイムを提案.
element-wiseにモデルの重みをベクトル演算することで,簡単にマルチタスクへの対応や知識の忘却,”A is to B as C is to D”のようなアナロジーの操作を行う.
ターゲットデータセットを用いてファインチューニングされたモデルがあれば,そのパラメータで演算することで,精度をほとんど下げることなるリソースを削減したタスクへの適応を可能に.
提案手法
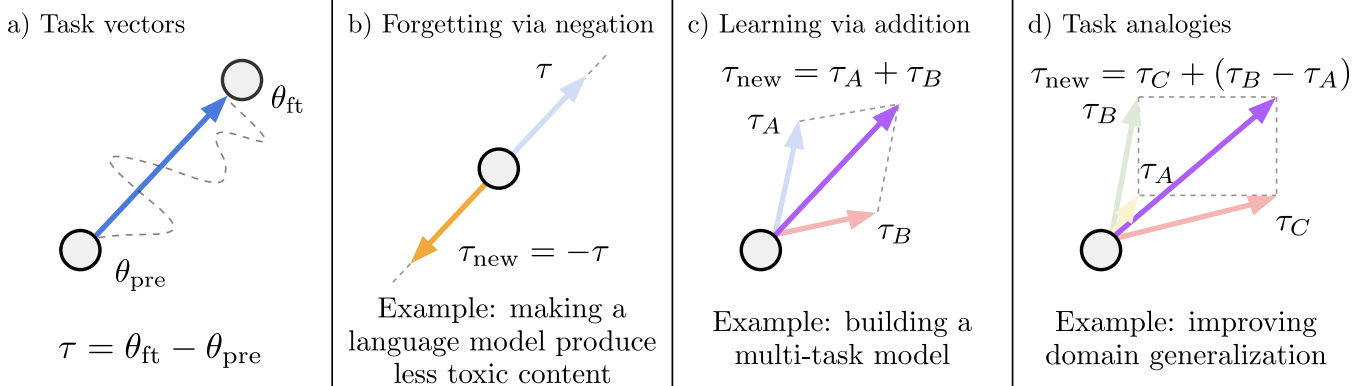
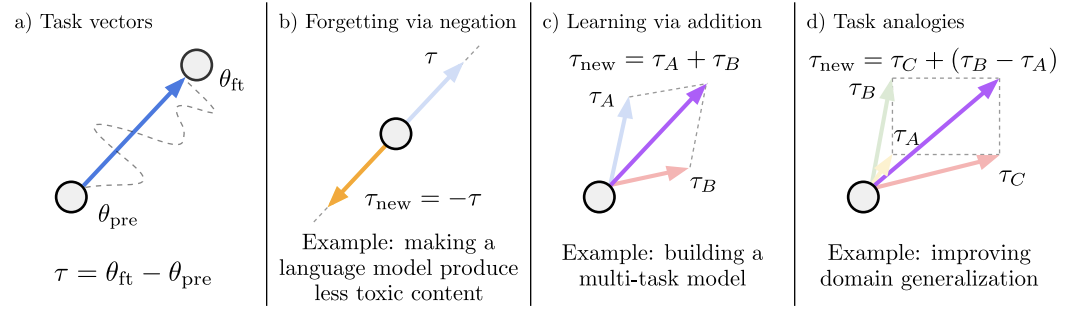
Task vectors
ファインチューニング後のパラメータから,事前学習済みモデルのパラメータを減算することで,ターゲットタスクに対するタスクベクトルを取得できる.
Forgetting via negation
用途:望ましくない行動(toxicな生成や顔の認識や個人情報のOCR等の倫理に反した情報の認識など)を取り除いたり,特定のタスクの知識を忘却させる
実装:
Learning via addition
用途:マルチタスクモデルとして性能を向上させたり,シングルタスクでの性能を向上させる
実装:
Task analogies
用途:ラベル付きデータが得られない場合や少量しか得られなかったタスクに対して,同様のタスク転移をアナロジーで構成することで,そのタスクに適応させる (”A is to B as C is to D”)
実装:”A is to B as C is to D” →
新規性
Task arithmeticを使ってモデルのパラメータを編集する新たなパラダイムを提案.
element-wiseな演算でタスク転移を可能にすることで,その操作はシンプルで高速で効率的
推論時にメモリや計算リソースの観点で追加のコストがかからない
ベクトル演算は容易で,マルチタスクベクトルによって立ち上がりの早い実験を可能にする(誰かがファインチューニングモデルを公開している条件のもと)
実験
Forgetting via negation
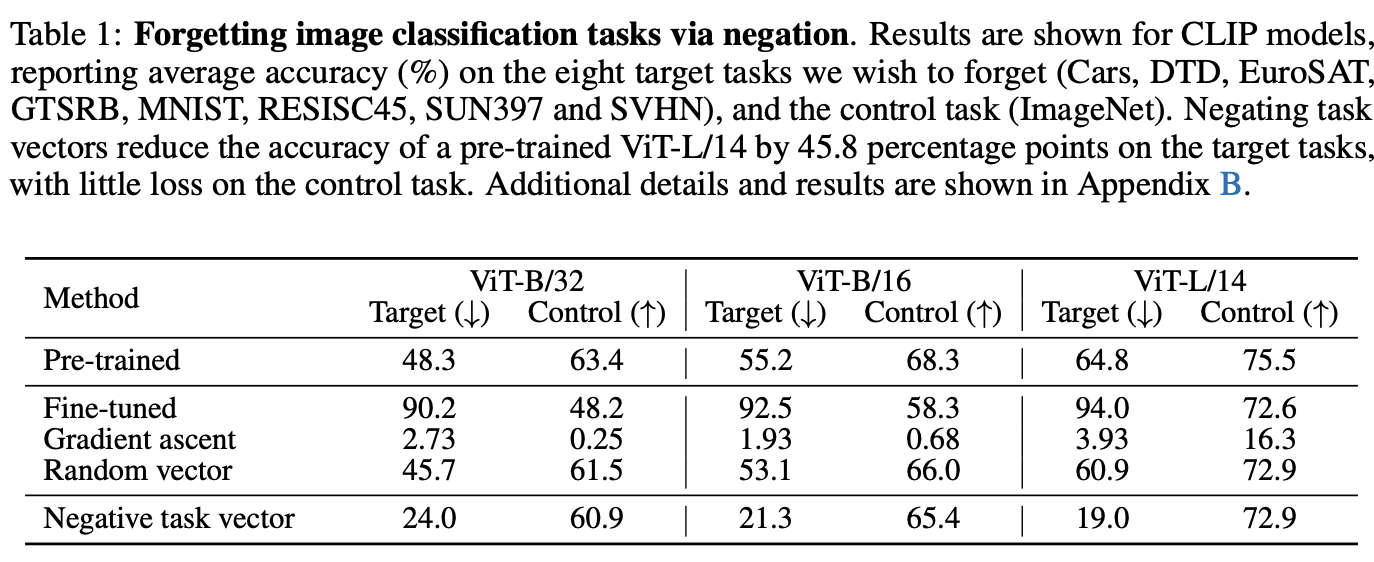
CLIPモデルを用いて,コントロールタスク(l性能を保持したいタスク)をImageNetとし,8つのターゲットタスクをnegationによって忘却させるタスク.
ベースラインのGradient ascentは勾配が上がる方向に(lossが上がる方向に)パラメータを更新するもの.
ViT-L/14モデルだと,ターゲットタスクの性能を上げつつ,コントロールタスクの性能低下はあまりなくパラメータ更新ができている
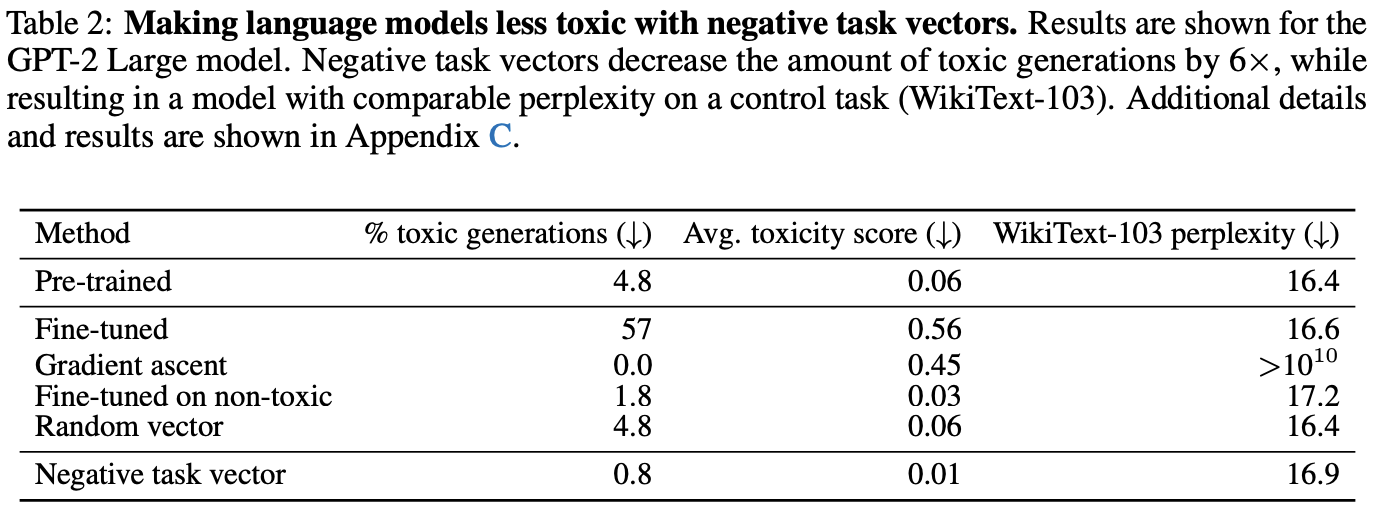
GPT2-Largeを用いて,Civil Commentsデータセットを対象に実験
toxicな生成を低減しつつ,WikiText-103のperplexityの性能低下を防ぐことができている
Learning via addition
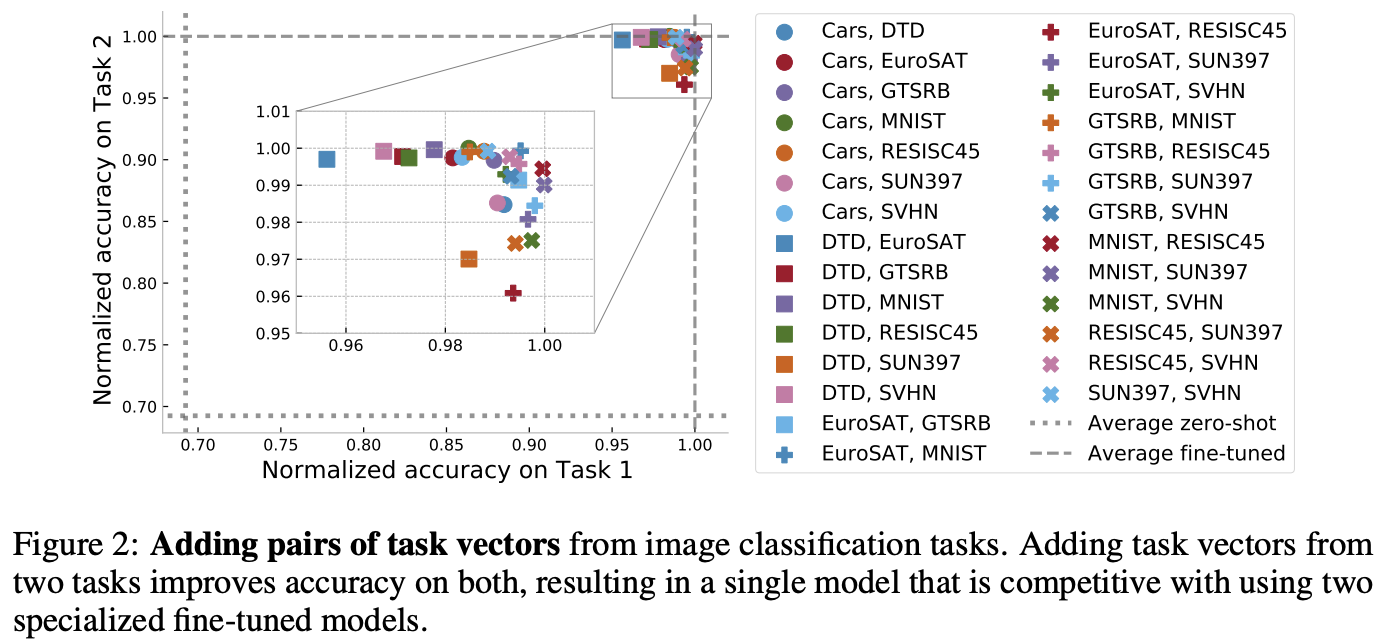
二つのタスクベクトルを加算して,マルチタスクに対応したパラメータを構築した結果.選び出して加算した二つのタスクへの性能は高い性能を維持している
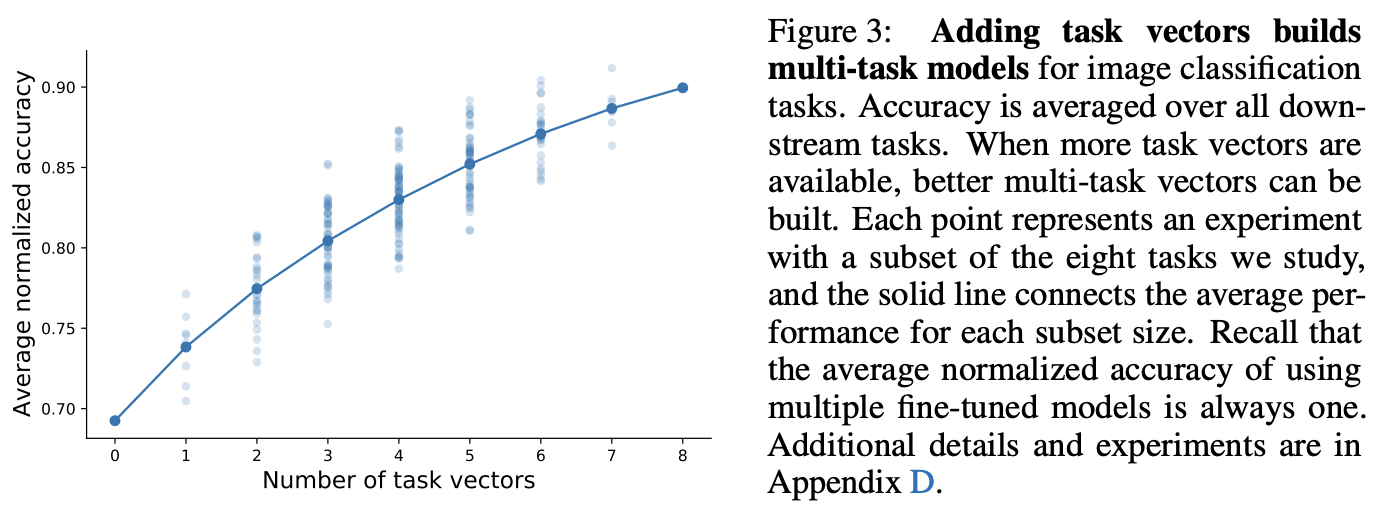
タスクベクトルを増やした時に性能が全てのデータセットに対して性能がどう変化するかを示す図
タスクベクトルの種類を増やすことで全てのタスクへの性能が向上していく様が見てわかる
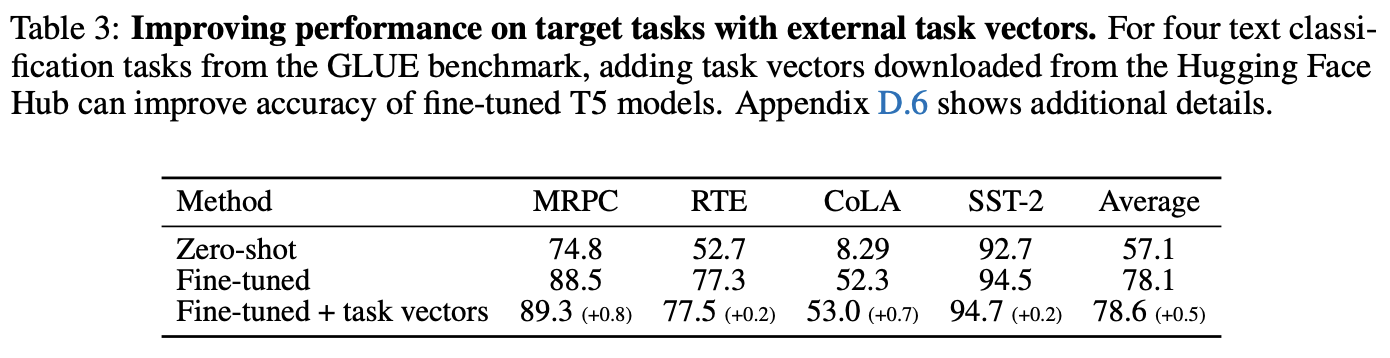
T5-Largeを用いて,GLUEタスクにおいて外部のタスクベクトルの加算を実験した結果
Huggingface Hubに転がっている427個の公開モデルがあり,それぞれのタスクベクトルを加算していき,検証データでベストな性能を出したモデルをセーブしてテスト
結果,GLUEでのファインチューニング+外部データのタスクベクトルを加算することで性能が向上することを確認
Task analogies: Domain generalization
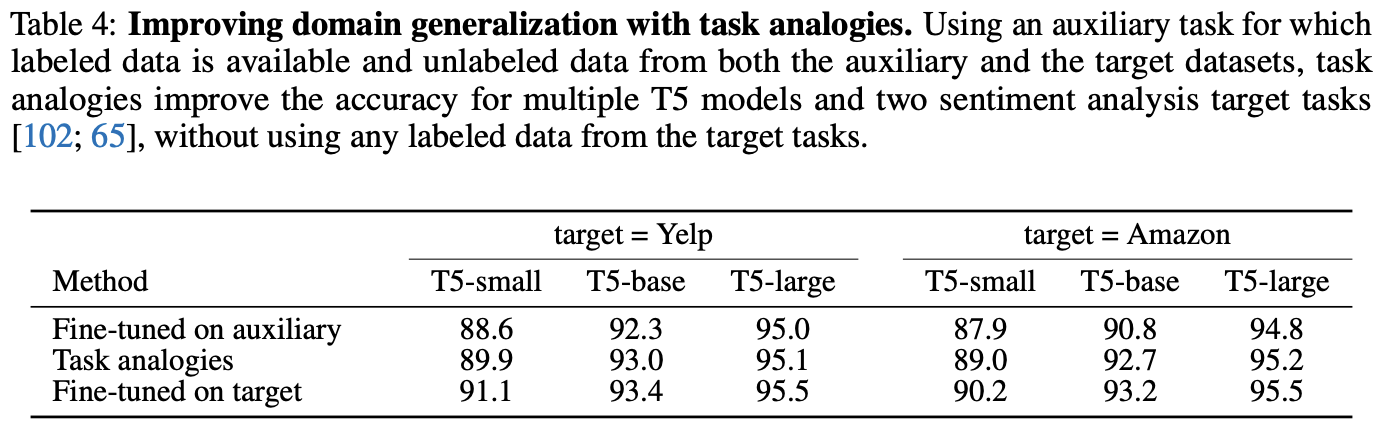
“Language modeling (LM) on amazon is to LM on Yelp as Sentiment analysis (Sent) on amazon is to Sent on Yelp”のようなアナロジーを調査
LMタスクのデータセットを対象とした転移を感情予測にドメイン転移できるかの検証
ターゲットに対する直接的なファインチューニングよりは性能は低いが,単にauxiliaryに対するファインチューニングよりは性能が高くなっている
Task analogies: Subpopulations with little data
(A, C)と(B, D)で同じクラスペア,(A, B)と(C, D)で同じスタイルペアのデータを対象とした実験
例えば,

タスクベクトルを使う方が常に良い結果となって,訓練データがなくアナロジーのみでも高い精度を示している
Task analogies: Kings and queens

queen, man, womanから,kingの新たなカテゴリーを学習するようなことができるか?の検証
まとめ
Similarity between task vectors

どれくらい複数のモデルが一つのマルチタスクモデルにcollapseできるかを理解するため,異なるタスクベクトル間のコサイン類似度を観察
基本的には,どのタスクベクトル間も直行方向に近づいている(類似度が0に近い)
しかし,digits認識同士は近くなっているし,衛生画像認識同士は近くなっているため,タスク空間の類似度は結果の説明の助けになりうる
The impact of the learning rate
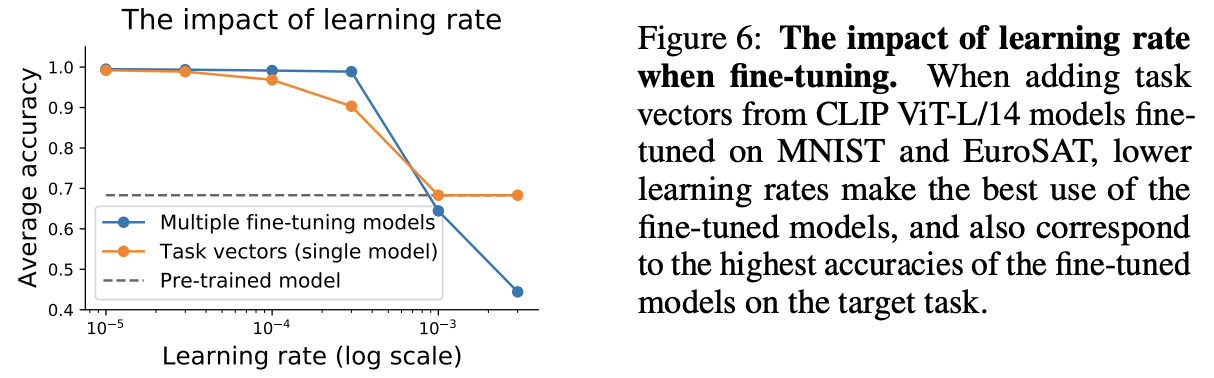
ファインチューニングの場合はあるところで性能がガクッと落ちるが,タスクベクトルだと緩やかに学習率の増加とともに性能が落ちる傾向
→ 学習率には注意を払うことが推奨される
The evolution of task vectors throughout fine-tuning
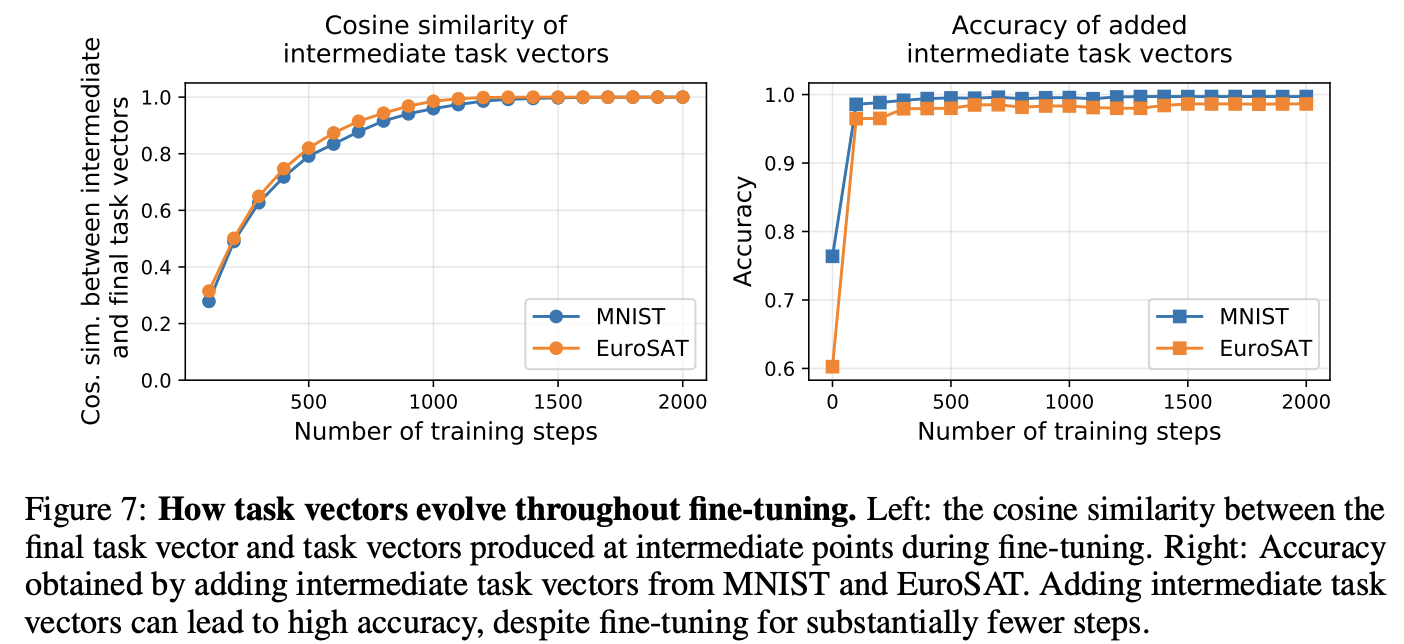
どのように学習していくかの経過を可視化
タスクベクトルは最終的なタスクベクトルの方向へ急激に収束する
精度も数百程度のステップのみで高い性能が得られる
→ 学習途中のタスクベクトルを使っても良さそうなため,計算リソースを節約しても精度へのダメージはほとんどなさそうか
Limitations
element-wiseなベクトル演算でパラメータを編集するため,同じモデルアーキテクチャであることと同じ事前学習済みモデルである制約がある
その他(なぜ通ったか?等)
Appendixが多すぎるので,詳細は論文を直接参照する
次読みたい論文
引用
@article{Ilharco2022EditingMW, title={Editing Models with Task Arithmetic}, author={Gabriel Ilharco and Marco Tulio Ribeiro and Mitchell Wortsman and Suchin Gururangan and Ludwig Schmidt and Hannaneh Hajishirzi and Ali Farhadi}, journal={ArXiv}, year={2022}, volume={abs/2212.04089}, url={https://api.semanticscholar.org/CorpusID:254408495} }