本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Disfluency Generation for More Robust Dialogue Systems
研究会: ACL
年度: 2023
キーワード: Speech Disfluency, DST, NLG
URL: https://aclanthology.org/2023.findings-acl.728/
DOI: http://dx.doi.org/10.18653/v1/2023.findings-acl.728
コード: https://github.com/4i-ai/BERT_disfluency_cls
データセット: DailyDialog, MultiWOZ, SIMMC2, Fisher
概要
非流暢な発話は対話システムの全てのモジュールに影響するエラー連鎖の原因になりうる(NLU, DST, NLG)
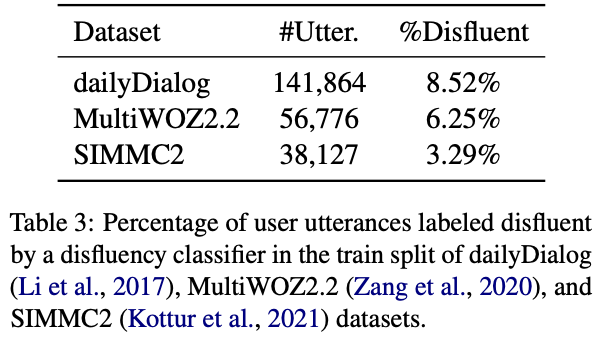
一般的に使われている対話データセットに非流暢な発話がほとんど含まれていないことを分析し(表3),流暢な発話を非流暢な発話にパラフレージングするaugmentation手法を提案
提案した手法でaugmentationした非流暢な発話を学習に用いることで,DSTとNLGの両方において性能が改善することを示す.
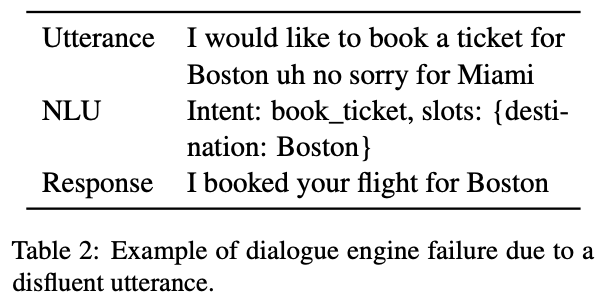
以下が非流暢性のタイプと非流暢性による対話システムのエラーの例

非流暢性の割合を分析した結果
提案手法
分類器によって流暢だと判定された発話を非流暢な発話にパラフレージング
Disfluent Paraphraser
LLM (T5) を用いて非流暢性の生成(非流暢性の修正をLLMで行う先行研究あり)
(BART, OPT, BLOOM等を使えば,同様の結果もしくはより良い性能が出るかも?)
LLMに非流暢性のseq2seqな生成タスクを学習させるために,非流暢な発話とそれに対応する流暢な発話のペアが必要
→ 大規模な学習データが存在しないため,few-shot learningを適用
ビームサーチで生成すると,元の流暢な発話の構造を保つ保守的なパラフレーズが多い
→ 元の発話とオーバーラップが少ない多様な発話を生成したい
→
Disfluent Identification
Paraphraserが積極的に非流暢な変換を行いすぎると,元の発話と意味が変わってしまう
分類器を用いて,元の発話をどの程度パラフレージングするかを決める
- disfluentなら,praphraserを用いない
- 低い確率でdisfluentなら,少し修正してdisfluentに
- fulentならaggressiveにdisfluentに
分類器にはBERTを用いる(先行研究 by Yang et al., 2020に従う)
新規性
- 公開されている一般的な対話コーパスには非流暢な発話があまり含まれておらず,対話システムのロバスト性に影響していることを分析
- LLMを用いて,流暢な発話を非流暢な発話へパラフレージングするフレームワークを提案
- 提案手法により,対話システムのロバスト性を向上
実験
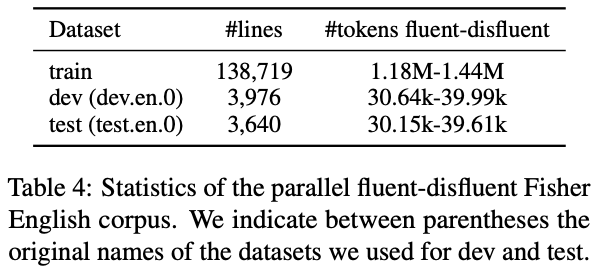
Paraphraserと分類器の学習にはFisher Englishコーパスを使用
SIMMC2でDSTとNLGを評価
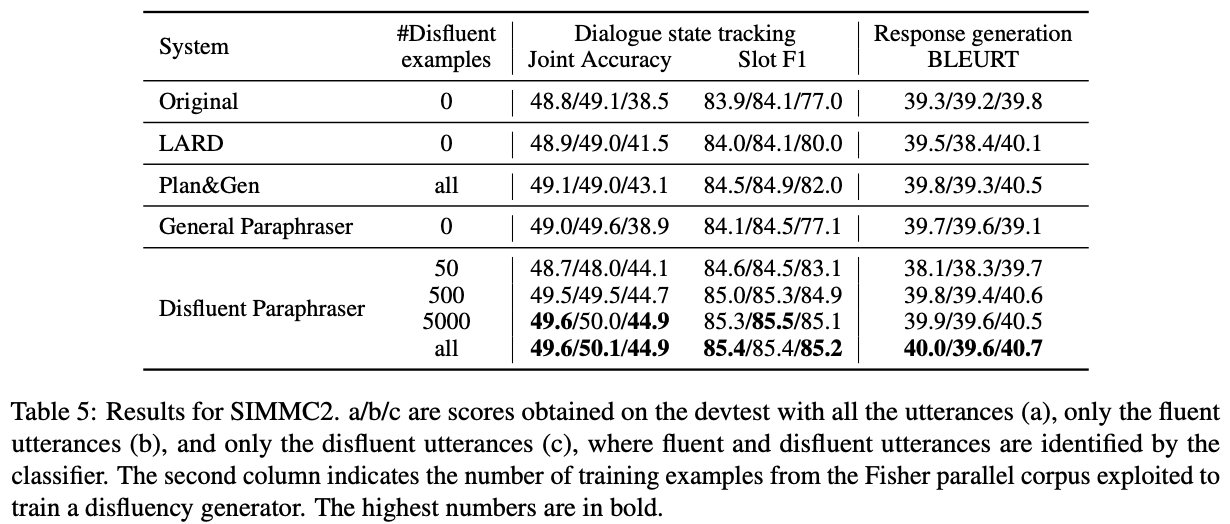
Original:オリジナルのSIMMC2で10エポック学習されたGPT2
General Paraphraser:非流暢性の生成で学習されていないスタンダードなT5 paraphraser
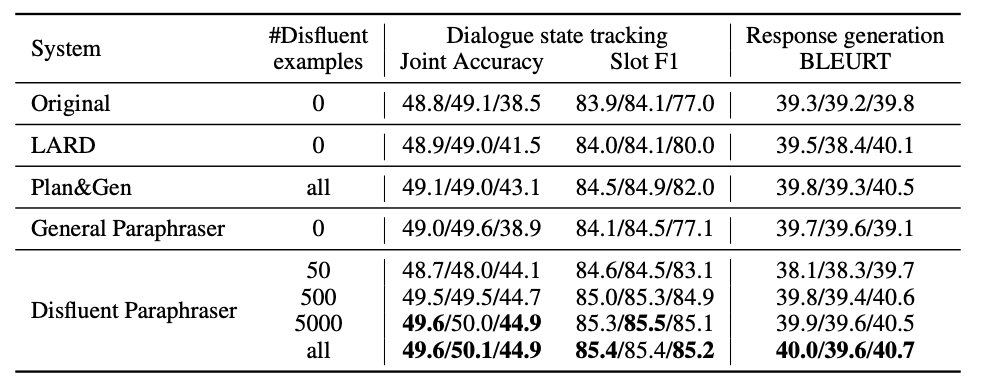
流暢性と非流暢性を混ぜても性能が向上するのは提案手法(Disfluent Paraphraser)のみ(表でいう(c)のスコア)
また,少なくとも500件は学習データがないと,提案手法ではBLEURTとjoint accuracyが下がる
まとめ
LLM (T5) を用いた非流暢な発話へのパラフレージングによるaugmentationデータを混ぜることで,対話モデルをよりうまく学習させることができ,非流暢な発話にロバストになることを確認
DST及びNLGでの性能向上を確認
その他(なぜ通ったか?等)
Limitations
- 利用可能な公開データセットはほとんどが流暢な発話でアノテーションされており,多様な非流暢性を含むもっと代表的な評価データセットを構築すべき
次読みたい論文
引用
@inproceedings{marie-2023-disfluency, title = "Disfluency Generation for More Robust Dialogue Systems", author = "Marie, Benjamin", booktitle = "Findings of the Association for Computational Linguistics: ACL 2023", month = jul, year = "2023", address = "Toronto, Canada", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2023.findings-acl.728", doi = "10.18653/v1/2023.findings-acl.728", pages = "11479--11488", abstract = "Disfluencies in user utterances can trigger a chain of errors impacting all the modules of a dialogue system: natural language understanding, dialogue state tracking, and response generation. In this work, we first analyze existing dialogue datasets commonly used in research and show that they only contain a marginal number of disfluent utterances. Due to this relative absence of disfluencies in their training data, dialogue systems may then critically fail when exposed to disfluent utterances. Following this observation, we propose to augment existing datasets with disfluent user utterances by paraphrasing fluent utterances into disfluent ones. Relying on a pre-trained language model, our few-shot disfluent paraphraser guided by a disfluency classifier can generate useful disfluent utterances for training better dialogue systems. We report on improvements for both dialogue state tracking and response generation when the dialogue systems are trained on datasets augmented with our disfluent utterances.", }