本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: Connecting Speech Encoder and Large Language Model for ASR
研究会: arxiv
年度: 2023
キーワード: ASR, LLM
URL: https://arxiv.org/pdf/2309.13963.pdf
DOI: https://doi.org/10.48550/arXiv.2309.13963
データセット: LibriSpeech, Common Voice, GigaSpeech
概要
ASRモデルのエンコーダとLLMを結合して,ASRモデルを構築(Whisper → Vicuna)
結合の方法として,全結合層,マルチヘッドクロスアテンシション,Q-Formerの3種類を試し,性能を比較
→ 組み合わせとしては,Wisper large-v2,80個の学習クエリを用いたQ-FormerとVicuna 13Bの組み合わせが良さそう
→ また,LLMのモデルサイズよりも,ASRモデルの性能の方がクリティカル(Whisper large-v2 > medium > base)
Seg-QF (Segment-level Q-Former)を提案
→ ASRモデルに入力可能な系列長を超えて処理ができる(i.e., Whisperは30sの制限)
→ 長い音声入力に対して,うまくいけばASR性能を向上できるが,入力が長すぎるとLLMのhallucinationを悪化させることも観測
提案手法
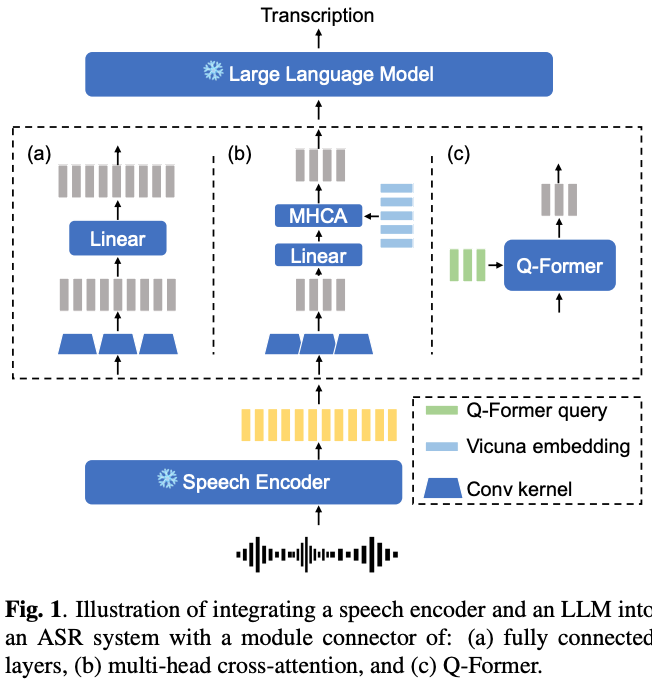
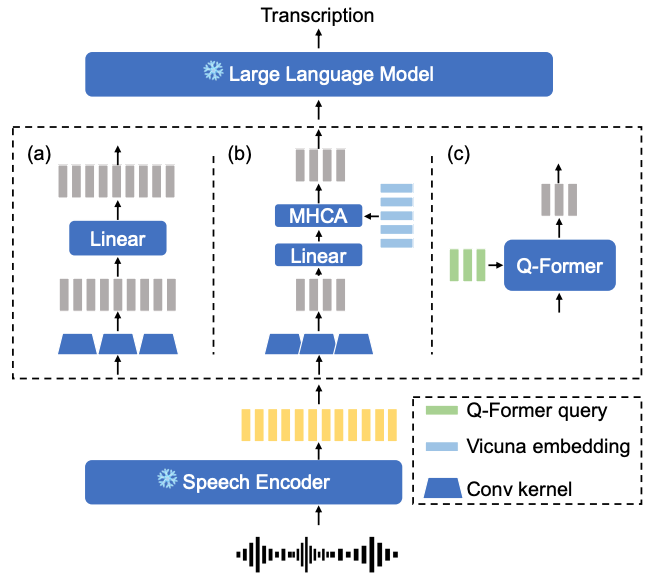
ASRモデルエンコーダとLLMの結合に3種類を試す
- 全結合層
- Conv1d → 線形層 → ReLU → 線形層
- マルチヘッドクロスアテンション
- Conv1d → マルチヘッドクロスアテンション
- クエリにはエンコーダの出力をConv1dにかけた埋め込み,キーとバリューはVicunaのテキスト埋め込み
- Q-Former
Seg-QF (Segment-level Q-Former)
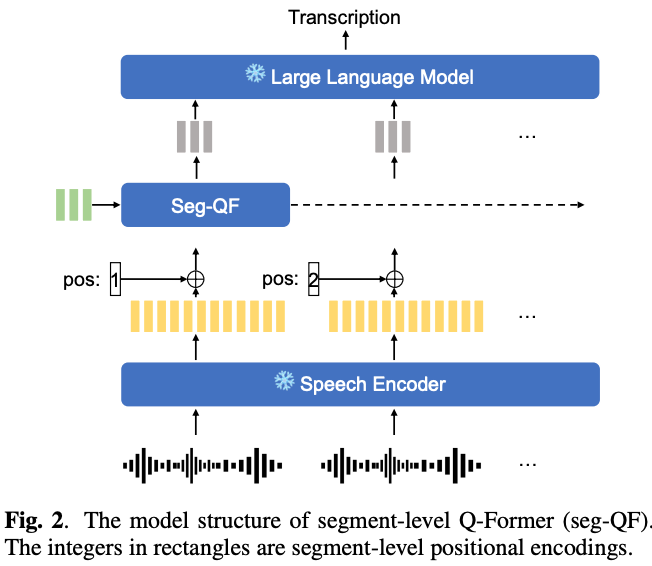
ASRの入力系列長を超えた時に,セグメントごとに処理をするアーキテクチャ
各セグメントの位置情報を埋め込むため,sinusoid positional encodingをASRエンコーダの出力に対して適用
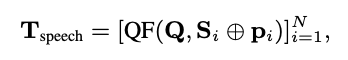
数式としてはこんな感じで,最後に各セグメントのQ-Formerの出力をconcatして,LLMに渡す
新規性
- ASRモデルとLLMを結合してASRモデルを構築する際,2つのモデルの結合方法として3種類を調査
- 全結合層
- マルチヘッドクロスアテンション
- Q-Former
- Whisper large-v2 + Q-Former + Vicuna 13BでWhisper large-v2よりもWERが向上
- ASRモデルの入力可能系列を超えても処理ができるSegment-level Q-Formerを提案
- 長い音声に対してもASRが可能に.ただし,長すぎる音声はLLMのhallucinationが悪化する課題あり
実験
結合方法の比較
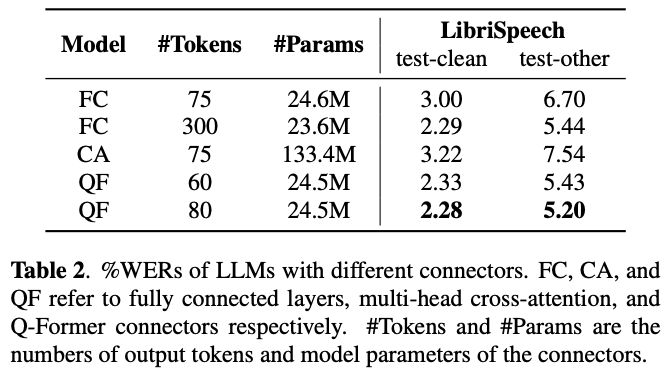
(多分FCのパラメータ数はどっちかがミス?)
全結合層かQ-Formerを用いるとトークンが多い方がWERは良い
マルチヘッドアテンション(CA)は,パラメータ数が多すぎるし,しかも性能も悪い
→ モデル検証には,Q-Formerが採用
Q-Formerの学習するクエリ数の調査
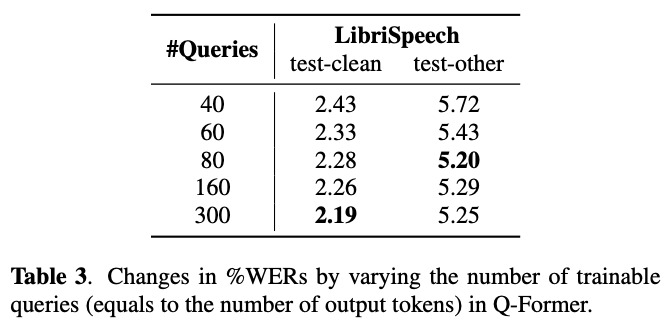
30s以内の音声に対しては,80まではWERが改善し続けている
LLMとASRモデルのエンコーダのサイズの調査
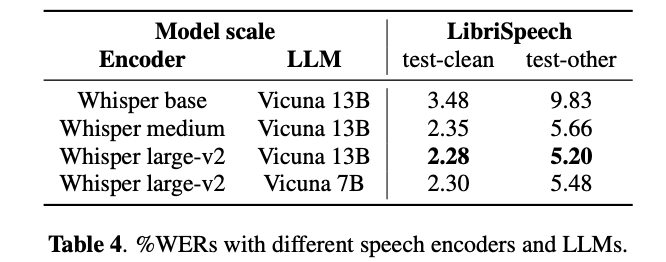
Whisper large-v2を使うと,LLMは7bでも良い性能が出ている
→ LLMのサイズより,speech encoderの性能の方が重要そう
4000h大規模訓練データで学習後の性能評価
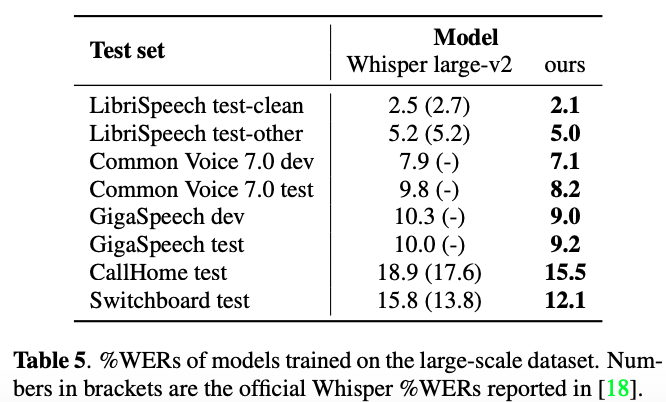
学習時はLibriSpeech, Common Voice, GigaSpeechで学習しているため,これらはin-domainで,CallHome, Swichboardがout-of-domain
in-domainでも,ベースラインのWhisper large-v2より性能が高くなっている
out-of-domainだと,最大で12%のWERの改善が見られている
Segment-level Q-Formerの性能評価
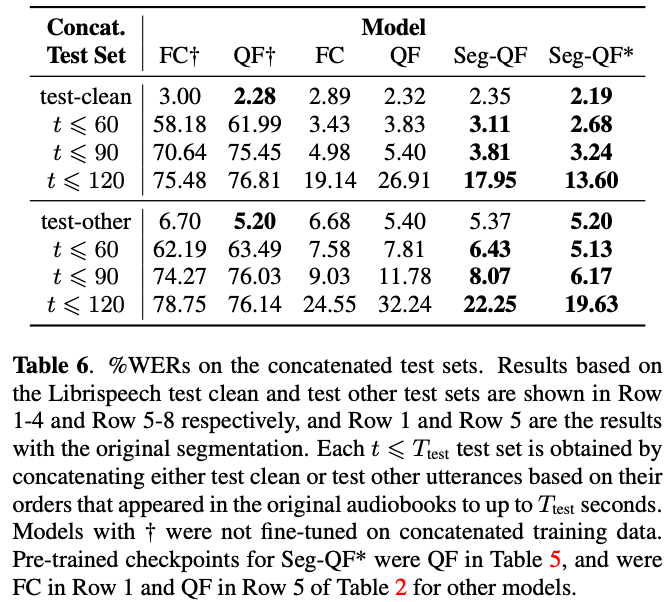
30sより長い音声で推論する時,ファインチューニングしていないと性能が悪い
長い音声でファインチューニングすると,全結合層かQ-Formerを用いると,長い音声でも良い性能を示せている
ただし,120sまで極端に長くなると,性能が悪くなる
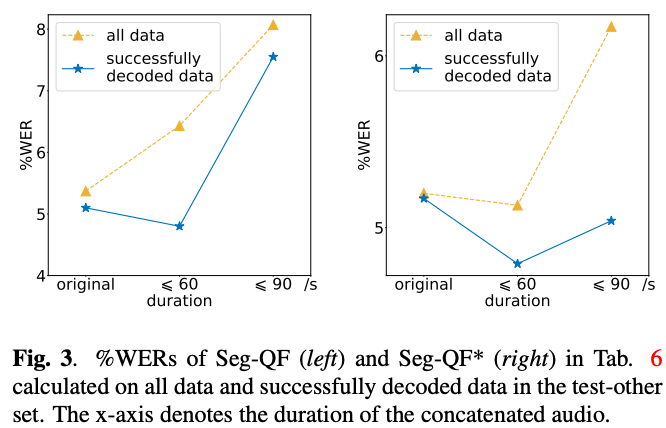
長時間の音声に対しては,デコードがうまくいくとWERは良いが(Fig. 3.),出力が繰り返されたり,長いチャンクが欠落するケースが多く観測される
その他
学習方法
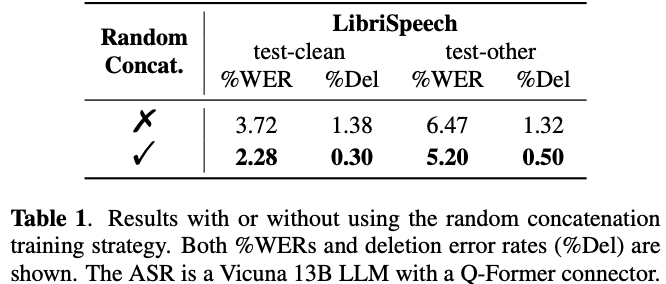
音声のない部分をマスクしてゼロパディングすると,Q-Formerが音声の終わりの方を無視するように学習してしまう問題が起きる
→ ランダムで音声を結合することで,deletion error rateとWERを改善できたため,論文中の学習はrandom audio concatenationのストラテジーで学習している
次読みたい論文
引用
@misc{yu2023connecting, title={Connecting Speech Encoder and Large Language Model for ASR}, author={Wenyi Yu and Changli Tang and Guangzhi Sun and Xianzhao Chen and Tian Tan and Wei Li and Lu Lu and Zejun Ma and Chao Zhang}, year={2023}, eprint={2309.13963}, archivePrefix={arXiv}, primaryClass={eess.AS} }