本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: A survey on empathetic dialogue systems
研究会: Information Fusion 64
年度: 2020
キーワード: survey, dialogue system, empathetic dialogue system
URL: https://sentic.net/empathetic-dialogue-systems.pdf
DOI: https://doi.org/10.1016/j.inffus.2020.06.011
データセット:
Keywords:
Artificial Intelligence,
Affective computing,
Dialogue system
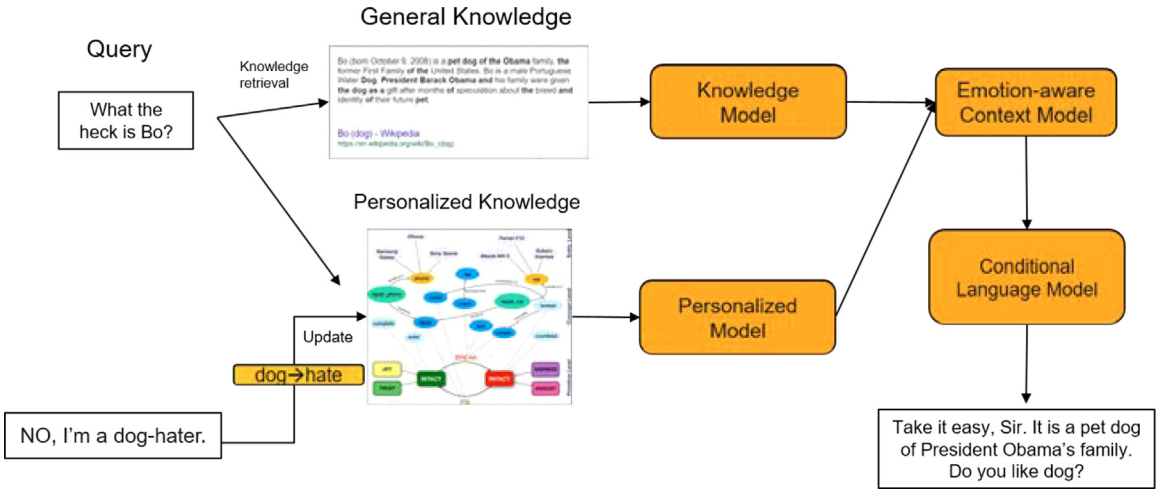
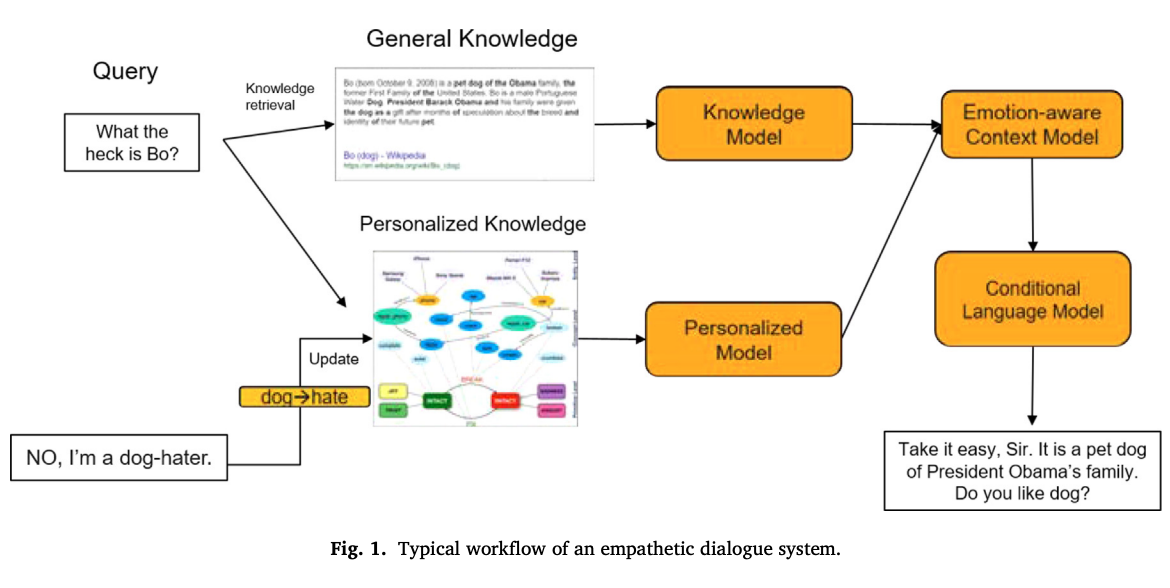
共感的対話システム構築の最終目的
→ユーザの疑問や悩みに応えること
どのような機能が対話システムの共感的な振る舞いを可能にしたのかという,機能の観点から対話システムのユニークな側面に注目する.
Personalization: システムの一貫性と整合性を高める働き.
→ユーザ固有の情報
emotion,personalization,knowledge の3要素が重要
Empathetic Dialogue System
感情の状態の感受や表現,個人的な嗜好,知識を強化する
3つの重要な特徴について
- emotional-awareness
- Personality-awareness
- Knowledge-accessibility
3つのサブトピックを扱う
- Perceiving and expressing emotion
- Caring each individual
- Casting into knowledge
過去10年ぶんほどをカバー
Propaedeutic background
backboneとして使われているアーキテクチャの紹介
-
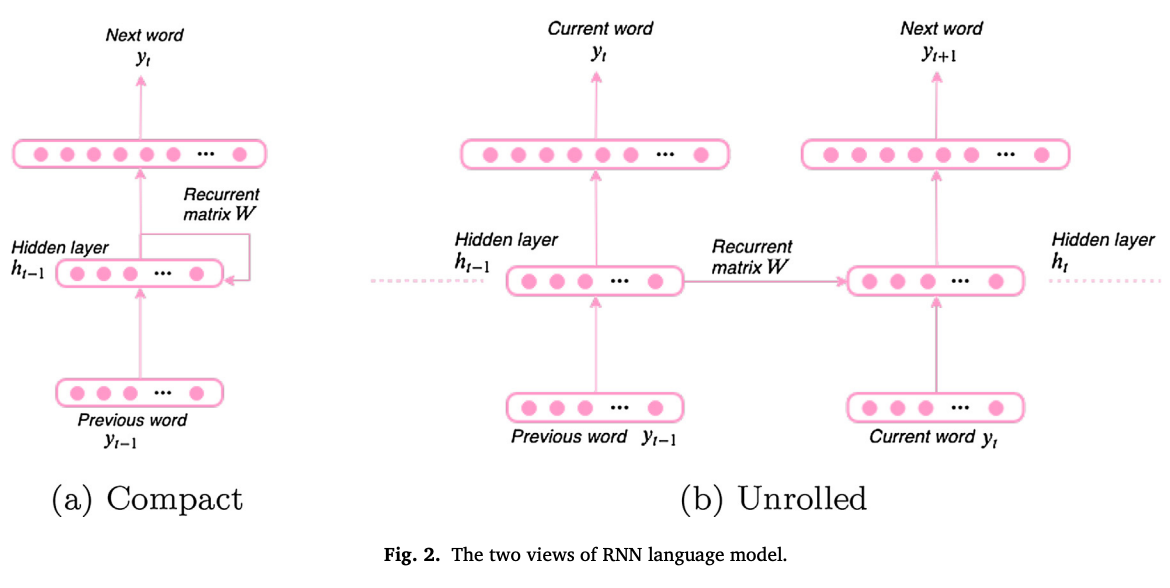
Neural language model 1. RNN (LSTM, GRUなど)
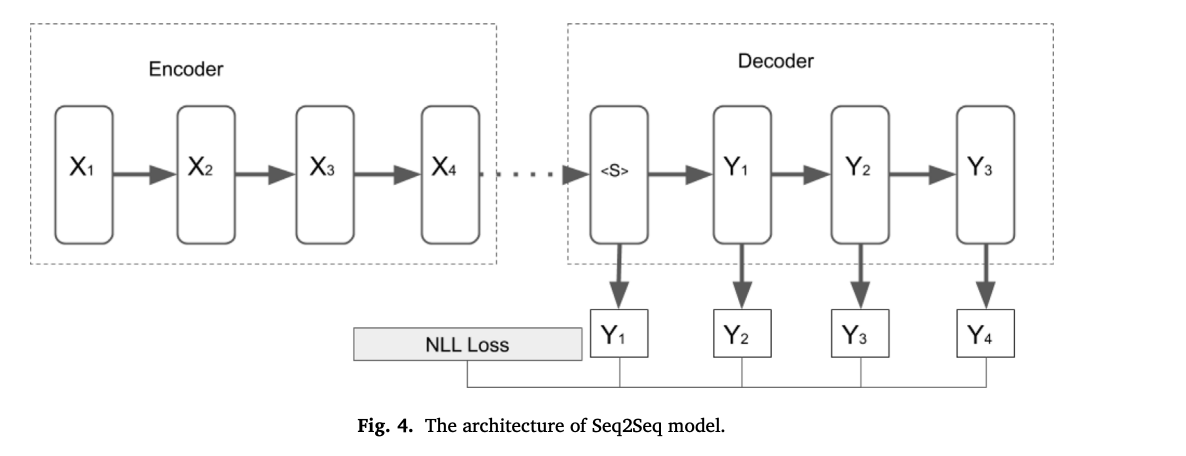
2. Sequence-to-sequence model
-
RNN
-
long short-term memory, LSTM 入力・忘却・出力の3つのゲート
-
gated recurrent unit, GRU gated関数は通常シグモイド関数.勾配のスケールを制限し,複数回の時間ステップの後に爆発するようにする.
-
-
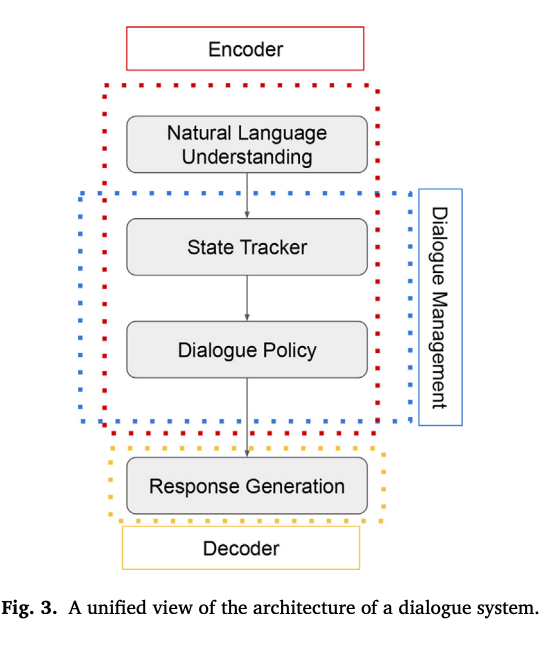
Seq2Seq modualizedなシステムは,通常以下の4パートからなる:
-
Natural Language Understanding, NLU 入力から構造情報を抽出する
-
a Dialogue State Tracker, DST
-
a Dialogue Polich, DP
-
a response generator 先行モジュールすべての出力に基づいた応答を生成する.
別名,エンコーダ・デコーダモデル.
条件付き対話生成のモデル化にはおそらく最も広く使われているニューラルアーキテクチャ.
エンコーダ,デコーダはそれぞれ,通常RNNをベースとしている.
- Attention mechanism
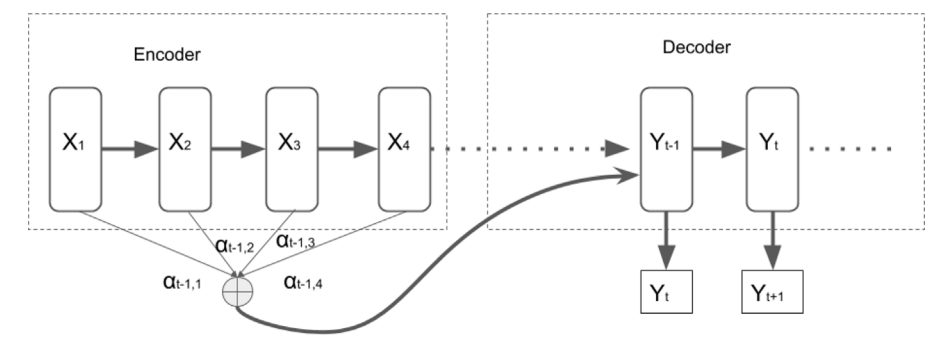
エンコーダが符号化できる最大ワード数の制限.入力単語数が大きくなると適切に符号化できない.
→デコーダが文脈の最も関連性の高い位置にアクセスすることが,この問題に効果的
RNNやseq2seqなどの,入力単語数の限界に対して対処できると,RNNやseq2seqでの問題の解消に一役買ったと紹介.
- Memory networks; MMN
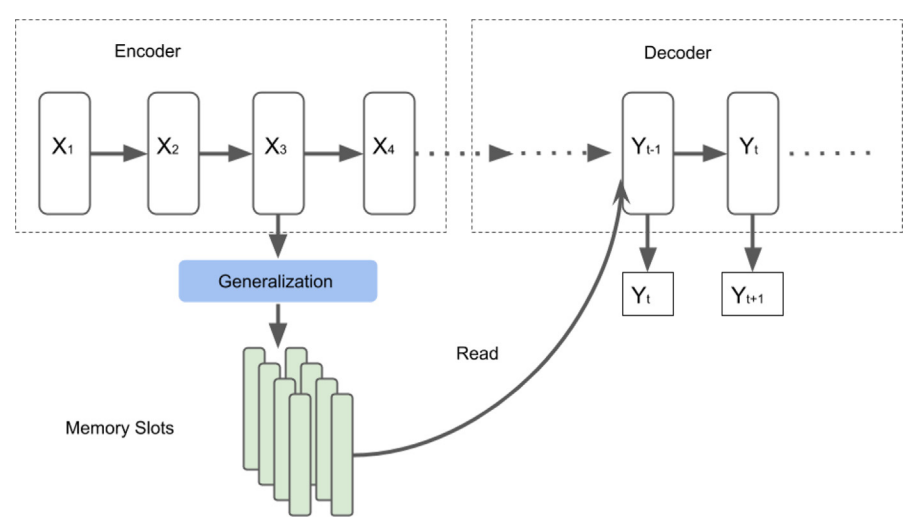
RNNの隠れ空間ではメモリは時間と共に更新されるものであるが,このメモリは小さかったり離れすぎていたりする.対話のような,文脈を理解するために長期的な記憶が必要な分野では上手くいかないことも.
内部に必要な情報を保持できないため,外部メモリの機能を実装したのがこのMMN
外部のmemory slotsに対して,attentionをかけてslotを更新するなどをする
- VAE, Variational AutoEncoder 条件付き確率分布に基づき,データ分布に近いように生成をする.
通常のオートエンコーダ:
入力→エンコーダが潜在変数を生成→デコーダ→出力(入力に似たものを生成)
VAE:
潜在変数がN(0,1)の確率分布に従うと仮定する.
条件付きVAE(CVAE):条件付き確率分布 P(出力応答 | 入力)をモデル化する.
-
GAN, Generative Adversarial Network Generator G, Discriminator D からなる.
画像生成から伝達学習までさまざまなタスクで大きな成果をあげている.
Generator vs Discriminator:
生成器(G)は分類誤差を最大にして識別器(D)を欺くように訓練され,Dは分類誤差を最小にするように訓練される.
-
RL, Reinforcement Learning(強化学習) 以下のような一般的に用いられる目的関数は,対話システムの現実的な目標と明確な関連性を持っていない.
-
尤度
-
ELBO ELBOを解く.
対話における各タイミングでの学習のフィードバックは,単語ごとではなく,まとまった文章が生成されたのちに与えられる.このため遅延報酬関数を使用できる.
論文の中でも,RLの重要性が何度も紹介されていた
Affective dialogue system
感情は,反応と社会的行動で文化的な作用であり,これは人と環境の関係によって連続的に発展していくもの
感情のカテゴライズは,心理学者と哲学者の間でせわしく,長らく議論されてきた
感情は社会的な機能も持つ.そして情動は意思決定に関連する尺度である可能性が示唆されている.人間の会話行動のエミュレートだけでなく,システムとユーザとの感情的なつながりを強化することができる.
本書における affective dialogue system
- perceiving emotion
- understanding emotion
- expressing and regulating emotion
↓
-
emotion-awareness 文脈の中の感情の表現に関係する,対話中のユーザの感情状態を検出できなければならない.
-
emotion-expressiveness 生成された応答に感情情報を取り入れることに関係する.
感情に関する理論は,感情の挿入がユーザとの感情の結びつきを強くするという利点をサポートしてくれる
Emotion analysis
一般的には,多くのcomputational modelは3つのカテゴリーに分けられる
- dimensional approach(次元的)
- discrete approach(離散的)
- appraisal approach(評価的)
Dimensional approach
感情をベクトル([覚醒]と[静寂]を表すもの)として表現する.
次元空間を持つことで,異なる感情の間でも類似度を計算できるのが利点
Discrete approace
感情をいくつかのカテゴリーに分類する.
カテゴリ数は設定によって異なってくる.(2,32,64,など.emojiで表したり)
Appraisal approach
感情と引き起こされたリアクションの関係について学習する
分布型
感情の別の表現方法.embeddingを使う.
メリット:
- 感情の種類が連続的になり,補完が可能になる
- DLの入力として直接利用できる
この利点は,感情のタイプを連続値として扱えること
Deep learningのinputとして扱えること
もう一つのタイプは感情を,実際の効果として重視する
satisfactionやpolitenessとして分類する
文や文脈から感情・感情を予測するタスク
会話が与えられた時,感情ラベルを事前に予測する=条件付き確率分布の学習と同義
aspect-base分析
目的:アスペクトと文の両方から感情ラベルを予測することを学習する.
文に複数のアスペクトが付与されているとして,その種類に応じて予測を行う?
対話システムによる感情ラベル予測では,現在の時間ステップまでの対話履歴しか見えないことがることに注意
Challenges
- 感情は曖昧な方法で表現される
- コンテクストから理由づけを必要とする
- 対話で現れた感情は,過去から継続していて,文脈的な感情の状態にとても依存している
- 発話者自身もだが,そのパーティにも影響を受ける
- さまざまなモダリティを合わせて感情を表している
Emotion-aware encoders
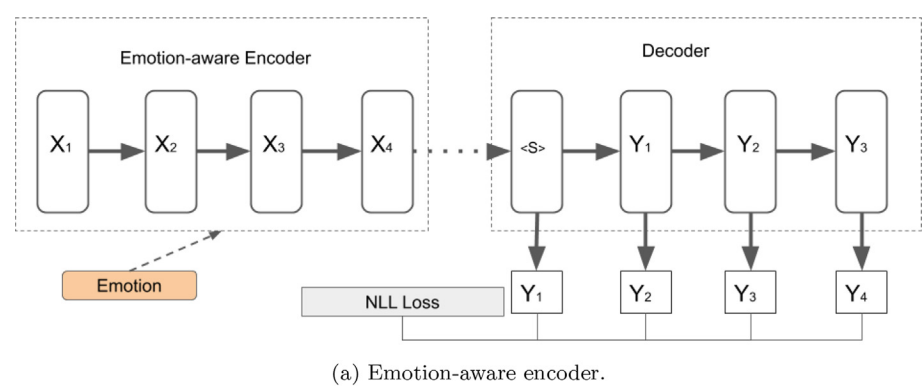
Emotion-aware encoderは,感情に関連した情報をエンコードする
得られる文脈ベクトルにも感情に関連した情報が含まれる.
モジュール化されたフレームワークは,POMDPとしてモデル化したものとして扱える
追加の特徴量として感情のラベルを与えることで機能する
ただし,テスト時は感情ラベルがない
→emotion detector(=追加の感情検出器)を加えて,暗示的に感情のラベルを推測することで機能させる
Emotion-expressive decoder
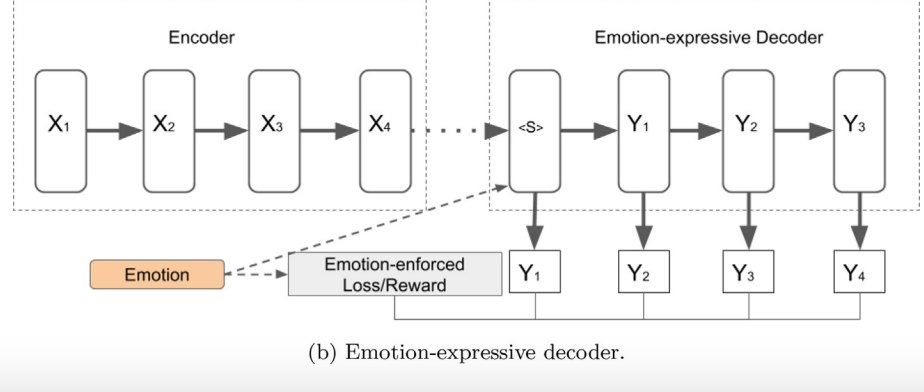
感情的なレスポンスを促進する目的で使われる
controllable variableとして直接感情を与える
モデルはCVAEやGAN,RLなどを使うことが多いらしい
controllable variableの想定
一つまたは複数の潜在的な変数が応答の生成に対して強制力を持っていること
そしてそのような変数が存在していること
潜在的な対話状態をモデリングするのに自然なアーキテクチャはCVAE
学習の際,微分できないことが多いので,誤差をフィードバックするにはRLを使うのが重要
Discussion
Challenges
- 感情のラベルの不足
- 対話のアノテーション処理に時間がかかるため,人手が不足.
weak supervisions を用いることで緩和可能:事前に学習された感情ラベルを使うとか,複数のデータソースを組み合わせて規模を拡大するとか
- 感情の評価
- 単語レベルでは感情の手がかりが微妙なこともある.
ユーザの本質的な感情と実際の認識にギャップがある可能性 →ユーザの誘導とギャップをノイズとして扱うこと.
- 他の目的における感情のcompliance
- ターンレベルでのcontrollable variableと生成される単語の依存性
Personalized dialogue system; PDS
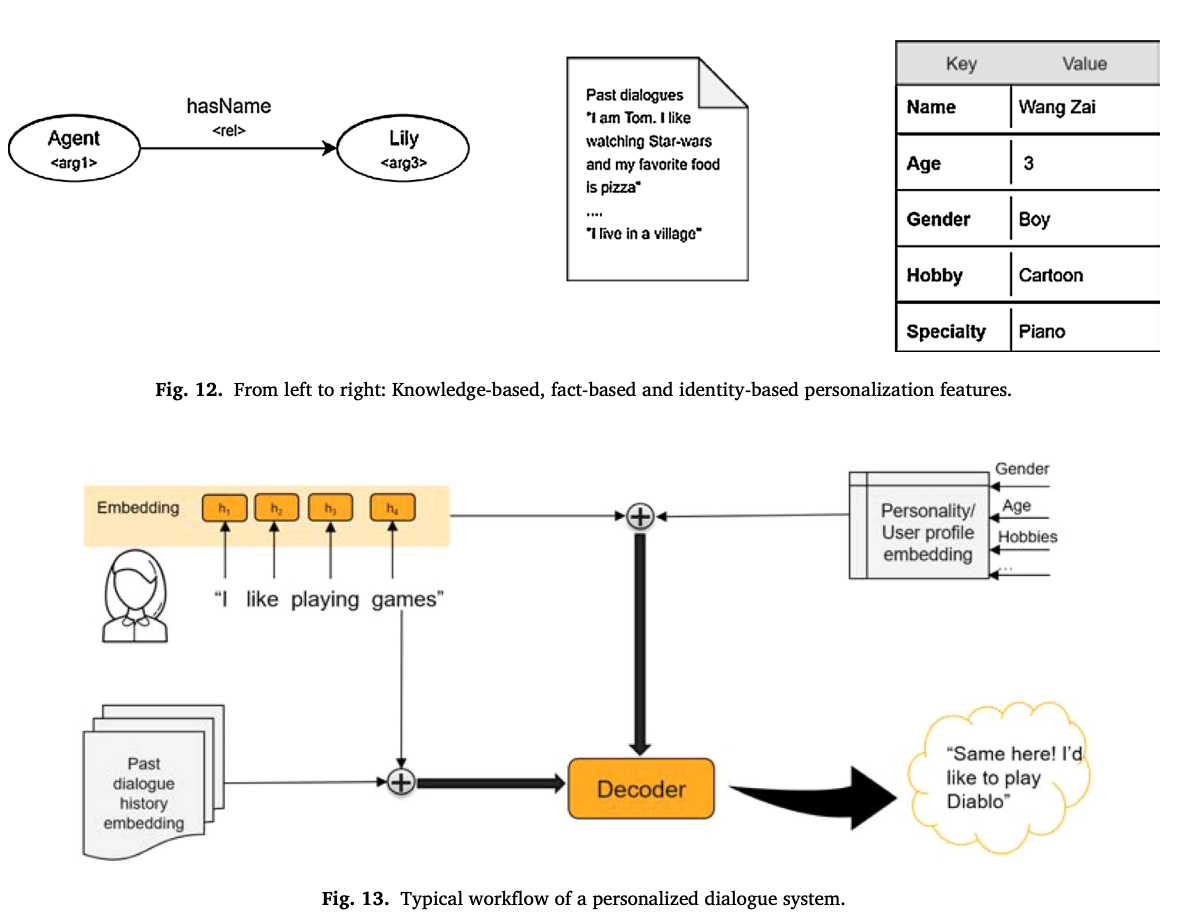
personalized informationは,話者の意図や継続的な状態を知覚したり,結果的に適したレスポンスを生成するのを成功させる鍵になる
User modeling
パーソナリティを表現する方法は,多くのパーソナリティ理論で重要になっている関心ごとである
このサーベイでは,user modelingの方法として,二つに分類される
- identity-based
- knowledge-based
Identity-based user modeling
もっともシンプルな方法で,identityを静的な属性として与える
identity-basedの特徴量は,信頼性があり,情報抽出するための追加のステップを必要とせずに直接的に扱うことができる
identity-basedの特徴量のソースは主に,registrationで収集したメタデータである
persona factsとidentity featuresはパーソナライズされた応答の生成に効果があるため,unstructured dataとstructured dataの双方を使う
identity-basedをニューラルネットに入れるときは,embedding layerを用いて,連続値のdense vectorにする
Knowledge-based user modeling
structured dataとpredefined rulesを用いる
identity-basedと比べると,これはユーザのメタデータの制限がない
structuredとunstructured information data sourceを両方使用できる
Personalized reasoningというタスク
knowledge baseから事実を取り出すことを目的にしている
Personalized response generation
- generative methods
- retrieval-based methods (ranking methods)
PDSのメインの目標は,適した応答だけでなく,ユーザのじゅう雨よう(重要?)な知識に基づいた応答を生成すること
ここでは二つのサブトピックの紹介があった
- personality-aware model
- personality-infused model
Personality-aware model
ユーザのパーソナリティ,もしくは会話のパーティに適応した応答を生成する
その応答には,ユーザの嗜好が含まれるということである
ユーザのプロファイルや会話履歴は,話者の記憶の中で異なる役割をはたす→メモリ(MMNの話など)
システムの中で多くのユーザの参加する大規模な環境においては,それぞれのユーザのタイプに十分なデータを持つのが難しくなりうる
→ユーザの知識を収集したり,転移することは可能
以降はtransfer learningの話がなされていた.RLも同様に使えるとのこと
Personality-infused agent dialogue systems
会話をスムーズで,柔軟で自然に行うために,システムにpersonalityを与える
3つのコンポーネントからなる
- Profiler Detector
- Bidirectional Decoder
- Position Detector
-
Profile Detector どのprofileのvalueが生成された応答の中で言及されるべきかを選ぶ
MLPを使う
-
Bidirectional Decoder profile valueが言及される中で応答を生成する目的のデコーダ
-
Position Detector decoding positionのスタート位置を予測する
ここで使うコンポーネントはbidirectional decoderで監視するように設計される
Position Detectorは,training dataをかえる性能があるらしい
pre-specificなエージェントのprofileに沿った応答生成ができるモデルを提供してくれる
persona representationの後,以下の提案があった
-
Persona Aware Attention それぞれのdecoding positionに対するAttention weightsを生成する
-
Persona Aware Bias デコーダのoutput layerの分散表現を差し込むことで生成分布を評価する
Attentive Memory Network; AMNの提案
おそらく個人だけでなく,所属するグループの影響を加味するためのモデルだと思う
コンポーネント二つ
- Attentive Encoders
- Knowledge-Store Memory Module
Knowledge-based dialogue system
current dialogue, personal background, external knowledge sourceからきた知識から探したり,コミュニケーションをとるプロセスを経る
→ knowledge graphなど
external knowledgeは重要な役割をはたすことができる
このシステムはたいてい二つの追加のコンポーネントを持つ
- knowledge encoder
- knowledge-aware decoder
これらによりcontextとexternal knowledgeの両方で応答に条件付けできる
Knowledge encoding
-
Structured knowledge language understandingで重要な役割
扱うモデルの変遷
BoW→Sequence→Data cell→Recursive graph
人の前処理やルールベースなどでフィルターをかけるステップが必要
-
Unstructured knowledge 制約が少ないため,扱えるデータの量が多い
分散表現に変換できるので,end-to-endのモデル
Knowledge-aware decoding
historical knowledgeとしてknowledge source→contextなどとinputを一緒に入力にかける
inputはembeddingされたもの
応答生成における2種類の知識ソース:
- 対話の履歴から得られるもの
- 事前予知的知識
-
Knowledge attention knowledge encoderの出力であるknowledge embeddingを使って,応答の生成に条件付けをする
文脈とknowledge embeddingのセットが与えられたら,関連する知識を読み取るか再認識する必要があり,それが応答性性の条件付けに使われる.
-
Copy attention mechanismをベースにしている
attentionを入力から単語を選び,コピーするためのポインターに使う
seq2seqをコピー機構で拡張することで,検索ベースの手法より優れた性能を発揮する事が示された.
単語は決められた単語の分布から取るか,knowledge baseからの単語をコピーすることで生成される
高階層のmemory architectureの学習の提案をしている人もいる
Future direction
empathetic dialogue systemに残る研究課題:
personalization, knowledge, and emotion の要素の組み合わせによる包括的な共感システムの構築なんかはあまり行われていなかった.
-
Multi-goal Management
-
コミュニケーションには多くのobjective(目的)が乗っている →複数の目的によって過負荷になる事がある.感情や性格,知識を取り入れることでさらに顕著に.
-
dialogue agentは全ての異なる側面に取り入れるべき すべての異なる側面を考慮する必要があるから↓
-
user's inherent states, communicating information, minimizing the communicative effortsなど これらを同時に達成するための最適解をいかに効率的に探索するかが問題となる
-
-
Explicit Affective Policy
- 感情は明示的な行動と考えられる
- agentが他の人の感情をミラーリングしたり,共感を示したりする 並列共感(相手の感情のミラーリング)と反応的共感に対して異なる戦略を取る事ができる.
-
Long-term Empathy Modeling
- 対話中での共感はlong-termである
- emotion, personality, knowledgeを静的,動的の双方で評価して,long-termで対応する 静的で動的:安定的なベースを持ちながら,変化もしやすい.長期的なデータ収集において変化に適応する会話モデルの構築が課題.
-
Dialogue Generation with Target-dependent Emotion
- 感情は,話者と会話の参加者にアタッチされた特定の次元であるとして,target-dependent emotionをuser modelingに合わせる 感情とターゲットの依存関係が省略されてきた.ターゲットに依存する感情をユーザモデリングと組み合わせることが望まれる(感情と人格の2次元の相関 ←共同でモデル化する必要性).
-
Dialogue Generation with Emotion Knowledge
- sentimental, emotionalな知識を使って,感情の状態を認識する
-
Incorporate Cues from Multimodal Input
- 複数のモダリティを使って共感を示す
- i.e. audio signals, body gestures
-
Personalized Diversifying Dialogue Generation
- ユーザに合わせて,生成する応答や検索する応答をカスタマイズする
- グループごとに多様性はあるが,同グループ内での多様性はかけるのが問題
-
Deeper Conversation and User modeling
- 与えられたユーザからのクエリに対して,統計的にもっともらしい回答を取り出すのがシンプルなメインの目標なのが現在
- 将来的には,会話ごとにモデルを作ったり,どのようにユーザの感情が変わるかを理解したり,重要な会話や嗜好を覚えたり,ユーザのニーズや意図を汲み取る以上のことをするようになる(?)
- ↑そのためのサブタスク
- sarcasm detection(皮肉検出)
- time expression(時間表現)
- named entity recognition(固有表現)
- anaphora resolution
- microtext normalization
- etc
引用
@article{MA202050, title = {A survey on empathetic dialogue systems}, journal = {Information Fusion}, volume = {64}, pages = {50-70}, year = {2020}, issn = {1566-2535}, doi = {https://doi.org/10.1016/j.inffus.2020.06.011}, url = {https://www.sciencedirect.com/science/article/pii/S1566253520303092}, author = {Yukun Ma and Khanh Linh Nguyen and Frank Z. Xing and Erik Cambria}, keywords = {Artificial intelligence, Affective computing, Dialogue systems}, abstract = {Dialogue systems have achieved growing success in many areas thanks to the rapid advances of machine learning techniques. In the quest for generating more human-like conversations, one of the major challenges is to learn to generate responses in a more empathetic manner. In this review article, we focus on the literature of empathetic dialogue systems, whose goal is to enhance the perception and expression of emotional states, personal preference, and knowledge. Accordingly, we identify three key features that underpin such systems: emotion-awareness, personality-awareness, and knowledge-accessibility. The main goal of this review is to serve as a comprehensive guide to research and development on empathetic dialogue systems and to suggest future directions in this domain.} }