本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: A Survey of Knowledge-Intensive NLP with Pre-Trained Language Models
研究会: arxiv
年度: 2022
キーワード: survey, NLP, knowledge-base, PLMKE, commonsense, encyclopedic, Knowledge-Intensive NLP
URL: https://arxiv.org/pdf/2202.08772.pdf
DOI: https://doi.org/10.48550/arXiv.2202.08772
データセット:
まとめること
- Knowledge-Intensive NLPの概要
- Knowledge Sources
- Encyclopedic Knowledge
- Commonsense Knowledge
- 最近のKnowledge Sourcesの特徴
- Knowledge-Intensive NLP Task
- Knowledge-Intensive NLP Taskの概要
- Knowledge-Intensive NLP Taskの特徴
- Knowledge Fusion Methodsについて
- Pre-Fusion Methods
- Post-Fusion Methods
- Hybrid-Fusion Methods
- 代表的なモデルの紹介
- Challengingなことと今後の方向性
- Unified PLMKEs Across Tasks and Domains
- Reliability of Knowledge Sources
- Reasoning Module Design
概要
事前学習済みモデルにより,モデルのcapacityは増加傾向にあるが,encyclopedicやcommonsenseを用いた,knowledgeableなNLPモデルの需要の高まりが生じている
**PLMKEs (Pre-trained Language Model-based Knowledge-Enhanced models)**についてまとめたsurvey論文
linguistic or factual knowledgeは暗示的にモデルのパラメータに保存される
→事前学習済みのNLPモデルがより汎用的な能力を持つことを一部ではあるが説明できる
今のpre-trained LMは,明示的なencyclopedicやcommonsenseのレバレッジ能力に欠けている
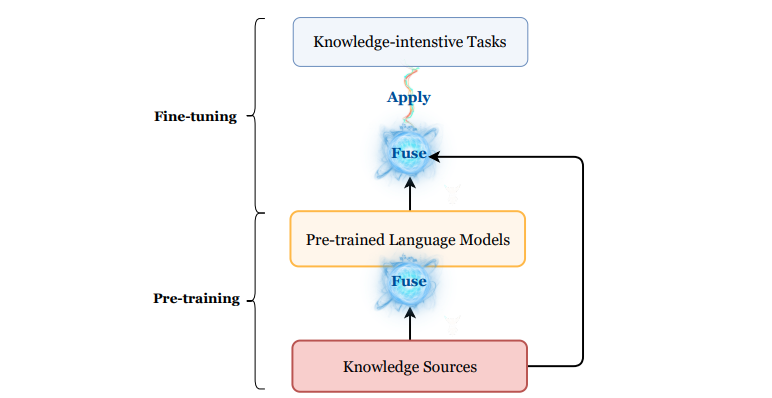
PLMKEsは,関連する外部知識を取り出すモジュールと知識を混ぜるモジュールがある
PLMKEsに関連した重要な3つの要素がある
- Knowledge Sources
- Knowledge-Intensive NLP Tasks
- Knowledge Fusion Methods
Knowledge Sources
Encyclopedic knowledge
エンティティに関する属性とエンティティ間の関係性をもった知識
Entity: person → Attributes: age → Relations: educated at
Wikipediaは大量のencyclopedicな知識を持っている
人物の経歴やイベントの背景などを含んでいる
一般的にはtripletsで構成されていることが多い
e.g. <Tom Hanks, occupation, actor>
Wikidataのような知識データがPLMKEsに広く使用されている
Commonsense Knowledge
日常生活のなかでの状況に関する知識
イベントとその影響を記す
e.g. mop up the floor if we split food over it / study hard to win scholarship / goat has four legs
commonsenseの特徴
多くの人の間で共有されている知識であり,コミュニケーションの中で暗示的に想定されている知識である
commonsenseもtripletsで表現される
最近のPLMKEsでは,ConceptNetとATOMICが外部知識として使用されることが多い
Knowledge Sourcesの特徴
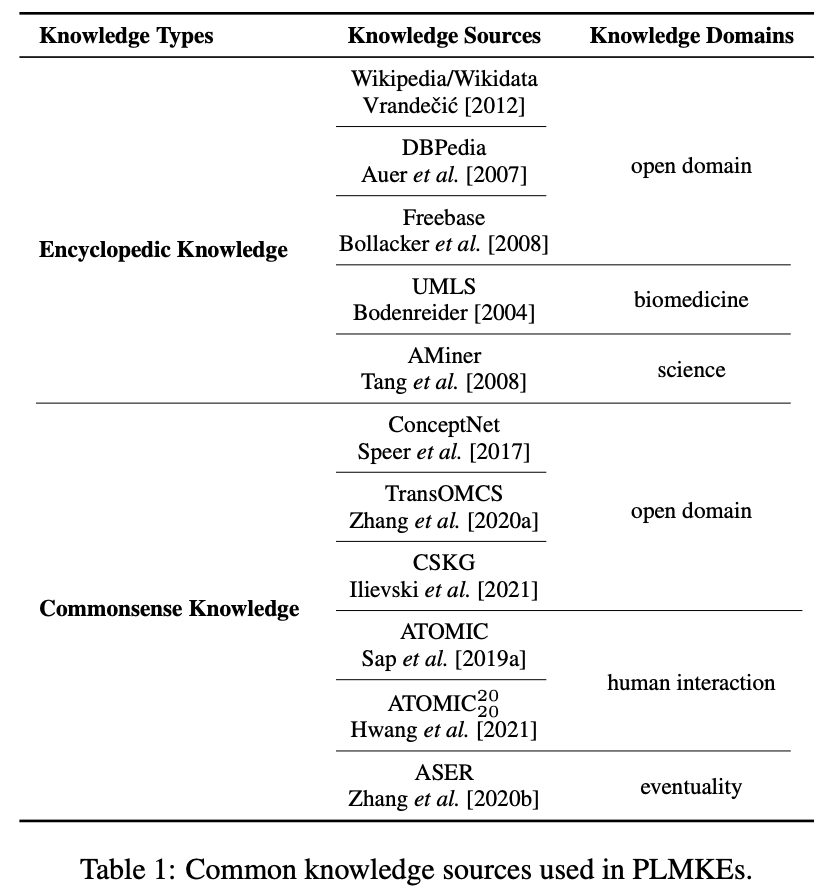
large-scaleでdiverse
現在のソースはより正確で安定的に作られている
アノテーションのプロセスは部分的に自動化されていて,非エキスパートにもaccessibleになっている
知識データがカバーするドメインは多様
オープンドメインのものもあれば,specificなドメインのものも
Wikipedia, DBPedia, Freebaseなどはオープンドメイン
UMLSやAMinerなどはbiomedicineやscienceの特定ドメイン
domain-specificなアプリケーションをブーストできる知識
commonsenseに関しては
ConceptNetやTransOMCSは複数のドメインのcommonsenseをカバー
ATOMICやASERはある特定のタイプのcommonsenseにフォーカスした知識ソース
Knowledge-Intensive NLP Task
概要
Knowledge-intensive NLP taskは必要とする知識ソースの種類で2つに分けられ,さらに詳細に分けることができる

-
encyclopedic knowledge-intensive NLP task encyclopedicの知識ソースを利用する
- open-domain QA
- fact verification
- entity linking
-
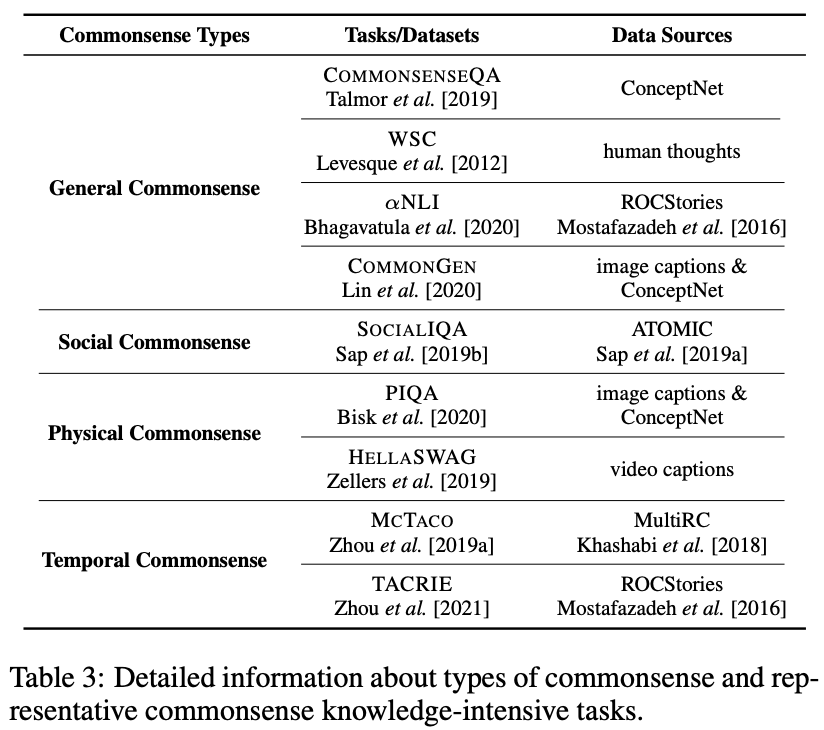
commonsense knowledge-intensive NLP task commonsenseの知識ソースを利用する
commonsenseの多様性のために,タスクのタイプ自体も多様化している
モデルが正確に日常のシナリオを理解し,応答するか否かのテストにフォーカスしたタスク
- General Commonsense
- Social Commonsense
- Physical Commonsense
- Temporal Commonsense
Knowledge-Intensive Taskの特徴
実際は,モデルにとってだけではなく,人間にとってもいかなる知識の参照なしに問題に答えるのは難しい.(バラクオバマの誕生日はいつ?など
しかも,外部知識が必要なのにinputとして必要な外部知識が渡されないため,とてもチャレンジングなタスクになっている
そもそも必要な外部知識にグラウンディングするモジュールをPLMKEsの設計に加えることを考慮するようになっている
Knowledge Fusion Methods
モデルが知識を統合するステージは二箇所あり,
- Pre-fusion; pre-training
- Post-fusion; fine-tuning
の二通りが考えられる(もしくはその両方のステージ
Pre-Fusion Methods
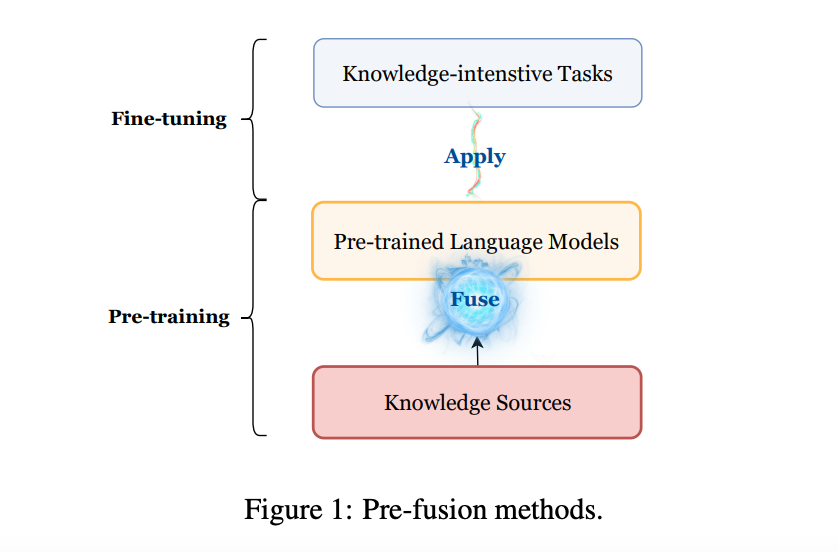
pre-trainingのステージで知識を統合する手法
モデルに知識を入力するため,構造化された知識データを非構造化データのテキストコーパスへと処理→モデルに入力
テキストデータとして知識を入力するため,大きくモデルのアーキテクチャを変更する必要はない
ただし,知識グラフのような構造化データを非構造化データへ変えることは難しいこともある
簡単な対処法はエンティティと関係性を結合するか,流暢な文章をconditional text generation modelに生成させるか
Zhang et al. 2019 | Agarwal et al. 2021 を参照(必要になれば読む
Post-Fusion Methods
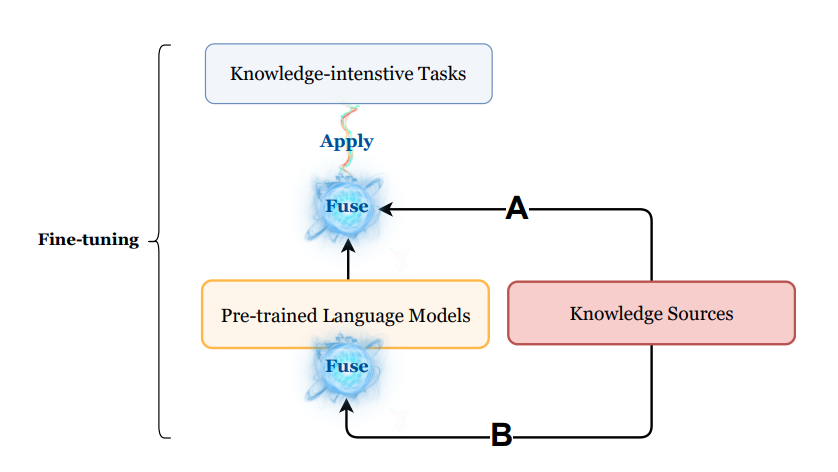
まず,関連知識をキャプチャする
次に取得した関連知識をGNNなどのエンコーダでembeddingを得る
- それを追加特徴量としてpre-trained LMに与える(図でいうA)
- 直接pre-trained LMに入力する(図でいうB)
Hybrid-Fusion Methods
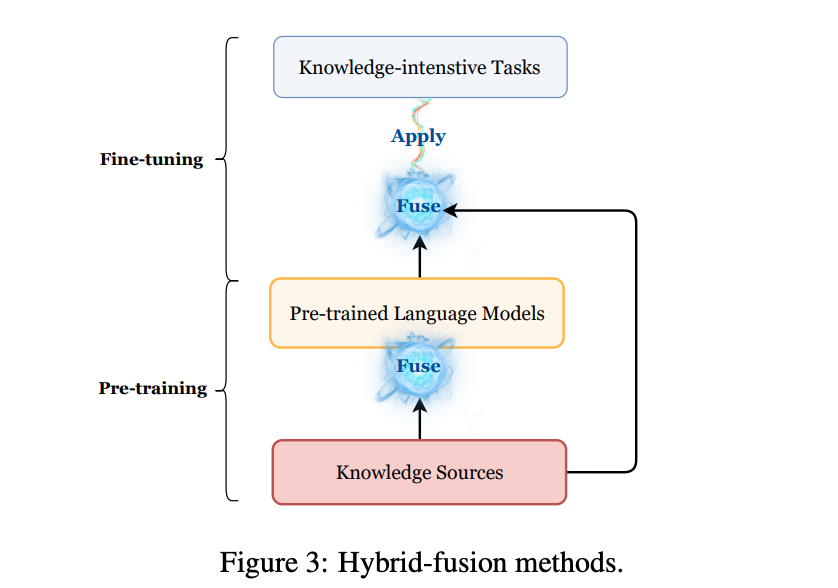
pre-trainingとfine-tuningの両方のステージで知識を統合する
追加の学習されるretrieverによりaugmentされたpre-trained modelは,fine-tuningのステージでより効果的にretrieverからの知識を活用できる
retrieval-augmented pre-trainingでhybrid-fusionが広く使われている
代表的なモデル
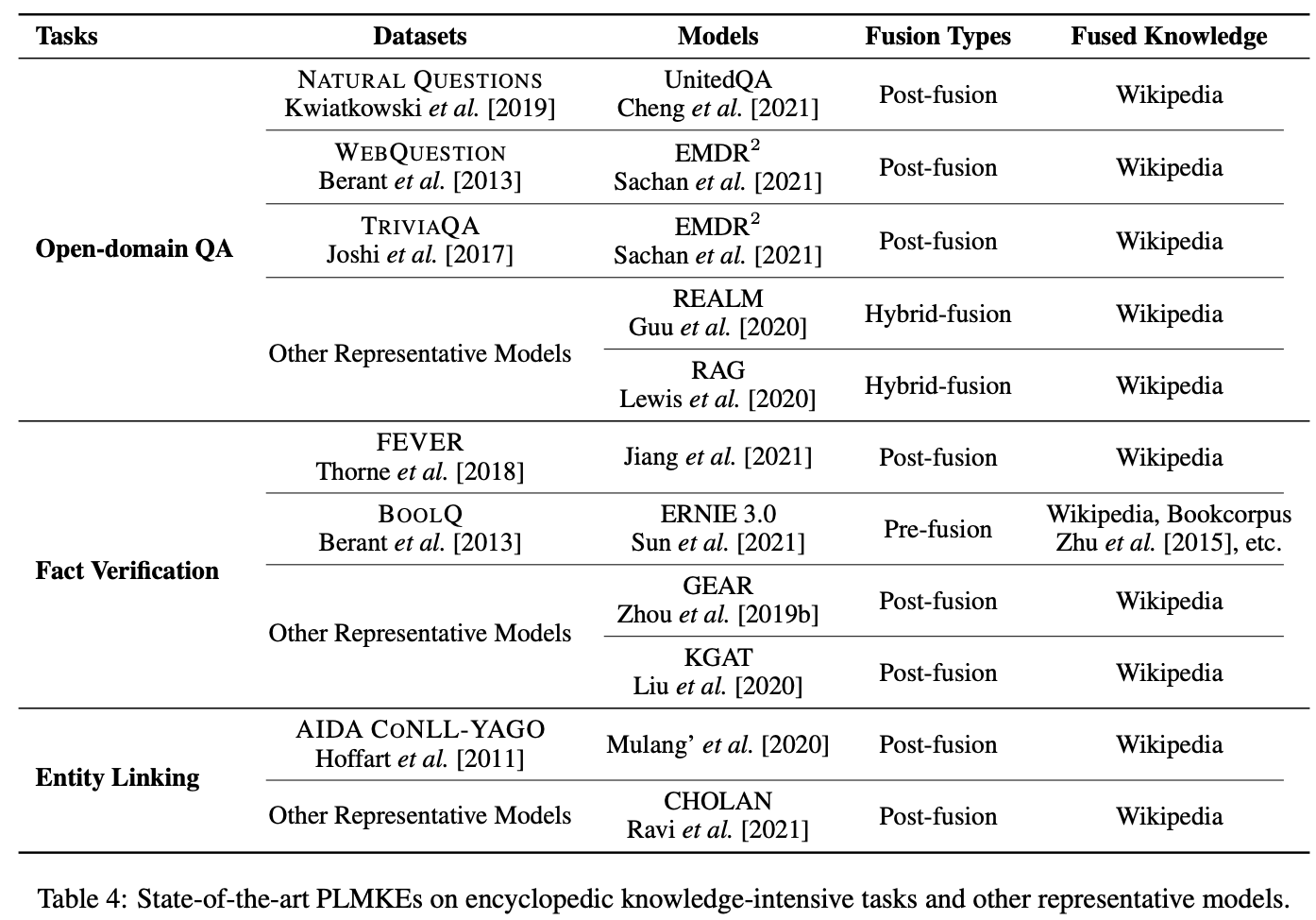
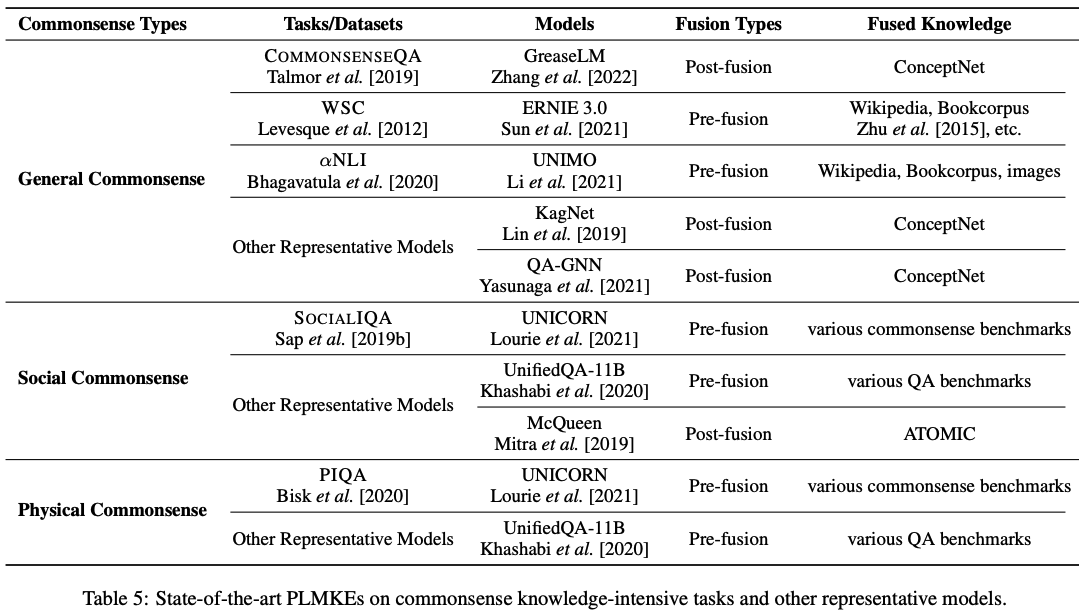
Table4/5はSOTAモデルを示す
encyclopedic knowledge-intensive taskにおいては,BOOLQをのぞき,全てpost-fusionを採用
commonsense knowledge-intensive taskにおいては,CommonsenseQAをのぞき,全てpre-fusionを採用
pre-fusionとpost-fusionの違いは何?
pre-fusionは,知識を事前学習のパラメータに暗示的に保存数る
最終的にどの知識がパラメータに保存するのかを決定するのは難しい
知識の引き出しや利用の難しさが増す
post-fusionは,明示的で具体的なテキストの知識を推論できる
post-fusionの利点は,commonsense knolwedge-intensive taskでは欠点になりうる
commonsenseはたいていテキストの中に暗示的に置かれていて,commonsenseの知識ソースのカバー範囲はencyclopedicの知識ソースのカバー範囲に比べればとても小さい
large-scaleなcommonsenseのソースの利用がたとえ有用だとしても,日常生活で使われる大半のcommonsenseを見落としがちなまま
→commonsenseにおいて,post-fusionがあまり効かないのはそのためなのでは?
Challenges and Future Directions
Unified PLMKEs Across Tasks and Domains
task-specificなモデリングでは進展がある
post-fusionとhybrid-fusionはencyclopedicで適用されているが,commonsenseでは採用できておらず恩恵が得られていない
異なるタスク間でのPLMKEsはユニークであるため,各タスク間で互換性がない
biomedicalやlegalの知識に関するknowledge-intensive NLP taskまで拡張されている
最近では,異なる時間や地域に存在する知識の多様性に対しても重要度を割り当てている
タスク間やdomain間でのunified PLMKEsの必要性がましている
Reliability of Kowledge Sources
知識ソースの信頼性に関して
多くのlarge-scaleな知識ソースは自動的な知識獲得アルゴリズムで構築されている
→スケールと正確性はトレードオフになってしまう
PLMKEsにおけるバイアスの増幅はバイアスのある知識ソースによって構築されてしまう
知識獲得アルゴリズムの見直しや使う前の知識ソースの注意深い精査が必要である
Reasoning Module Design
Reasoningはknowledge-intensive NLP taskを解く上で重要なステップである
commonsenseを考えるときは手順を踏んで,複雑な状況を把握する
e.g.
まず,床が綺麗でないことを把握
こぼした食べ物を踏んで他の人の靴が汚くなったのだろうと考える
↑上記状況を踏まえて,モップをかける意図が生まれる
人間のような日々の状況を認識する能力を獲得するには,multi-hopなreasoning moduleが必要になる(上の例みたいな形