本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: 知識源との一対多関係を有する対話コーパスによる発話生成
研究会: NLP
年度: 2022
キーワード: dialogue system, knowledge-base
URL: https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/B2-3.pdf
データセット:
概要
ある文脈において利用可能な知識は一意とは限らず,実際に利用された知識意外にも利用可能な知識は存在する可能性がある
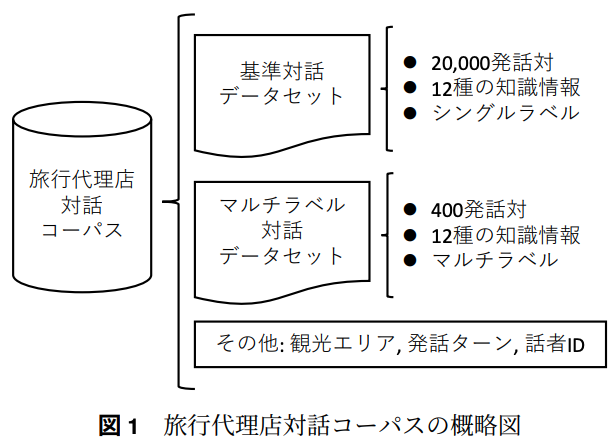
→ 旅行代理店における対話を題材として,基準対話データセットを作成(知識が一意)
→ 基準対話データセットを元にマルチラベル対話データセットを作成(知識が複数対応)
マルチラベル対話データセットを発話生成モデルの生成に用いると,多様で適切な応答が可能になることが示唆
提案手法
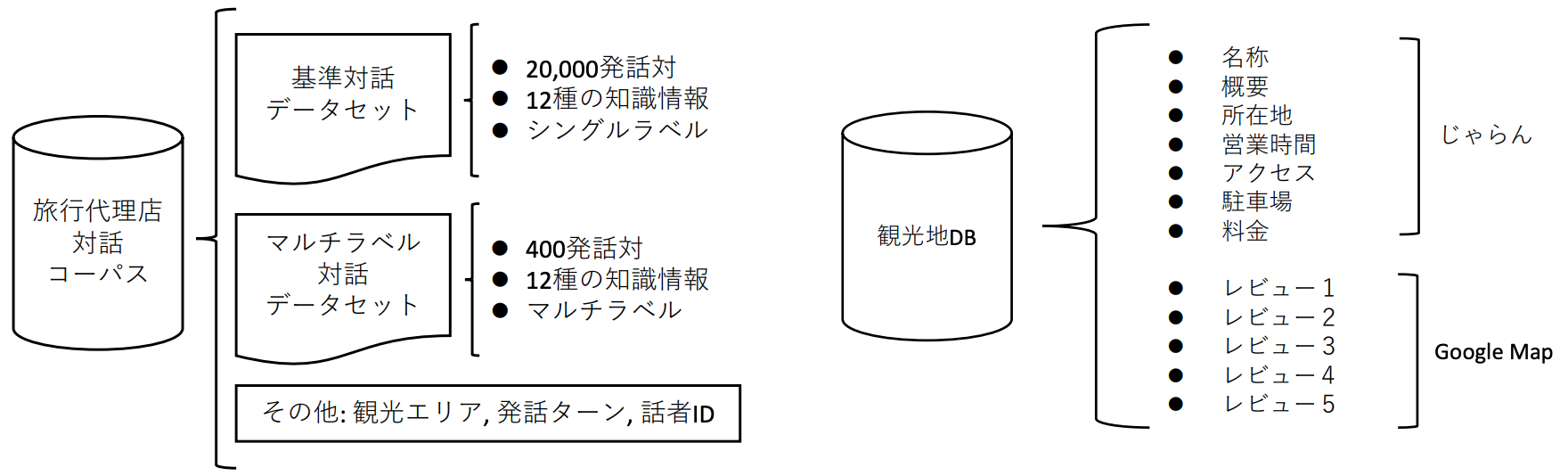
基準対話データセットの構築
クラウドソーシングを利用して,東京と大阪の観光地441件を対象に,観光地に関する対話おw収集
知識情報として,基礎情報はじゃらんからスクレイピング,レビュー情報にはGoogle Map APIを用いて取得
店発話は,知識情報をなるべく用いて発話し,使用できる知識情報源は最大で2つとした
相槌など知識情報を使用しない発話にはnoneのラベルを付与
マルチラベルデータセットの構築
利用していない知識は,「利用できない知識」ではなく「利用していない知識」
→ 基準対話データセットから400件を抽出し,対象の発話において利用可能な知識をアノテーション
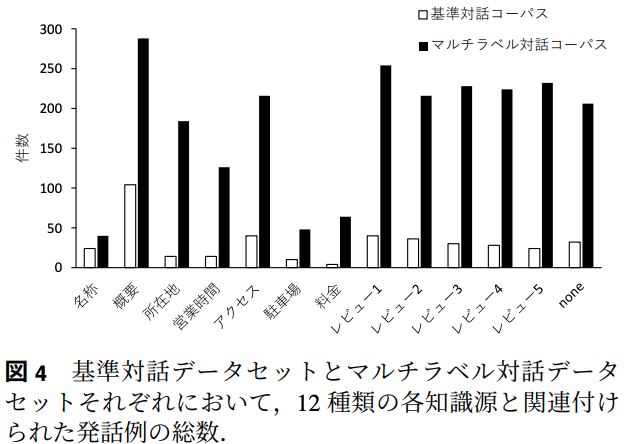
基準対話データセットの分布とマルチラベル対話データセットの分布を比較すると,多くの知識源が利用可能であるとわかる
新規性
一つの発話に対して複数の知識を対応させたマルチラベル対話データセットを作成
実験
Laboro製BERTを用いて利用可能な知識情報を選択
→ TransformerベースのNTT製大規模対話モデルhobbyistを用いて,知識情報を用いた応答生成
まとめ

BERTを用いた知識選択
シングルtestが0.46,マルチtestが0.90
適切な知識が選択できていれば正解なので,マルチが高くなるのはそれはそう
マルチラベル対話データセットを使用した応答生成は,全て文脈として正しく,知識を反映した多様かつ適切な生成ができていた