
本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: 対話システムはどのように話すべきか
研究会: 日本音響学会誌
年度: 2022
キーワード: 聞き手反応, dialogue system
URL: https://www.jstage.jst.go.jp/article/jasj/78/5/78_283/_pdf
DOI: https://doi.org/10.20697/jasj.78.5_283
データセット:
概要
「聞き手反応」をキーワードに,対話システムが発する音声をどのように生成するべきかという観点から音声対話システムとの自然な対話の実現に迫った研究の紹介.
聞き手反応
会話は話し手と聞き手の相互行為により産出されるもの
聞き手の反応を「相槌表現」として次の分類(Den et al., 2011)

聞き手の行動の観察は分析上不可欠であるが,音声対話システム研究ではほとんど考慮されない
人はシステムに対して,(人同士の対話と異なり)ほとんど聞き手反応をしない
人は,どのようにして声でシステムを操作するかを学ぶ
→ 機械は機械であり,人と同じようにコミュニケーションができないことを知っている
聞き手反応を誘発する話し方
音声対話システム vs 人における違い
- 発話タイミングを含むターンテイキング
- 話し方
- 人同士の対話における発話は,必ずしも明瞭かつ流暢ではない.
高津ら(2018)の研究では,人同士の対話にのみ存在する話し方の特徴を要因に分解し,次のコードで表す.


そして,以下の3条件でWoZ対話的なことを行う


発話計画例と実験の結果は次のとおり

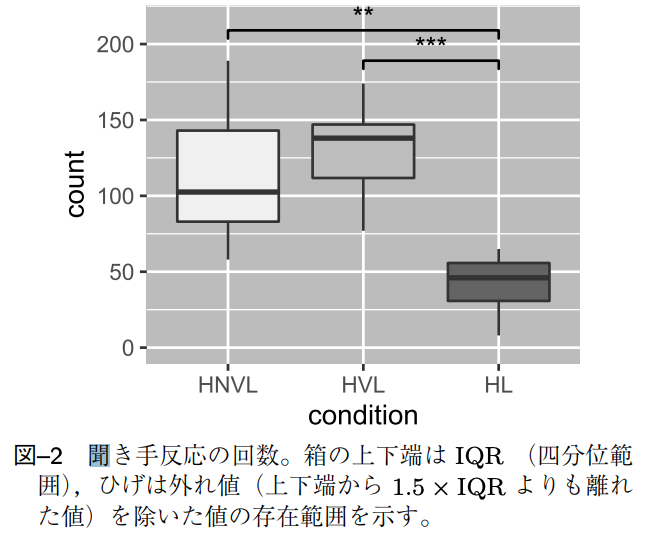
機械的な発話をすると,聞き手反応が減る
自発音声コーパスを元にした音声で話すエージェント(飯塚ら, 2019)
読み上げ音声コーパスではなく,自然な会話コーパスを用いて音声合成を訓練することで,読み上げと会話の音声のギャップを埋めうる
しかし,そのような試みは少ない
以下が考えうる要因
- 声のプロと違い,普通の人々の音声は正確性,明瞭性に欠けるから,音声合成に相応しくないという思い込み
- 会話音声の多様性.テキストだけでは説明できない音声のパラ言語的な特徴の変動が読み上げ音声に比べて大きく,モデル化が相対的に困難なこと
- 会話コーパスの小ささ.音声合成ではデータりょうが品質に直結するが,会話コーパスの場合,話者一人当たりのデータ量が少なく,音声のモデル化が困難なこと
- 筆者ら研究チームでは,とりわけこれがネックだった
- → ニューラルボコーダ(高木, 2019)の登場によりインパクトに
実験として,読み上げ独話音声コーパスJSUT vs 自発対話音声コーパスUUDB(宇都宮大学パラ言語情報研究向け音声対話データベース)
音声合成にはTacotron 2,スペクトルからの波形生成にはMelGAN
UUDBでは女性話者1名のデータでfine-tuning
MMDAgentを利用して音声対話システムを構築(研究仮説を検証するため)
国当てクイズの対話シナリオ
実験結果とその対話動画視聴から得たアンケート結果
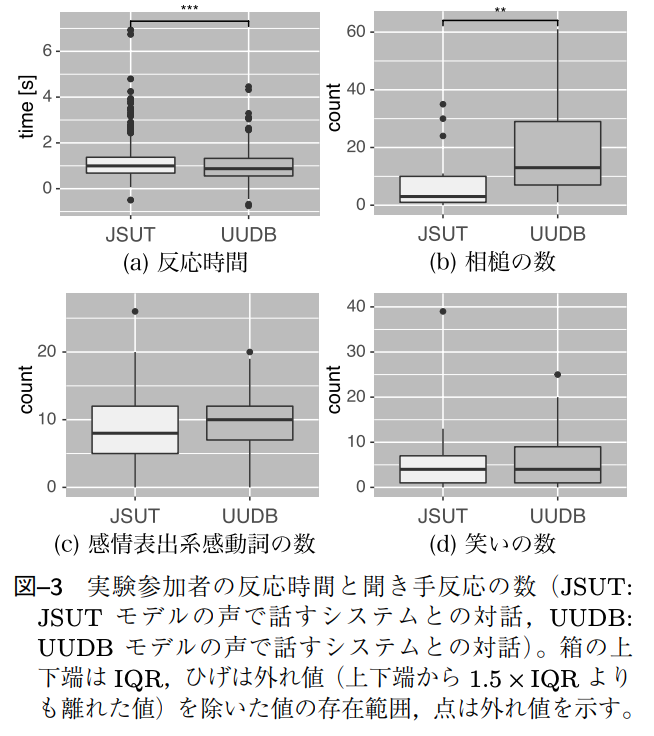

自然な会話コーパス(ここではUUDB)を元にした合成音声で話すシステムとの対話の方が,人同士の対話に近い振る舞いをしている.
感情表出系感動詞及び笑いの数に有意な差は認められず
「不気味の谷」???
まとめ
自然な音声対話の実現を望むならば,もっと本物の音声コミュニケーションと真剣に向き合わなければならないのではないか?
その他(なぜ通ったか?等)
次読みたい論文
引用
@article{2022, author = {森 大毅}, doi = {10.20697/jasj.78.5_283}, journal = {日本音響学会誌}, number = {5}, pages = {283-288}, title = {対話システムはどのように話すべきか}, volume = {78}, year = {2022}, bdsk-url-1 = {https://doi.org/10.20697/jasj.78.5_283}}