本記事において使用される図表は,原著論文内の図表を引用しています.
また,本記事の内容は,著者が論文を読み,メモとして短くまとめたものになります.必ずしも内容が正しいとは限らないこと,ご了承ください.
論文情報
タイトル: 分類モデルBERTによる不整合生成文の検出について
研究会: NLP
年度: 2022
キーワード: dialogue system, NLI
URL: https://www.anlp.jp/proceedings/annual_meeting/2022/pdf_dir/B2-4.pdf
データセット: 日本語SNLI
概要
ニューラル文章生成において,文章としては自然だが,内容が事実とは異なる**事実不整合(factual inconsistency)**が問題
→ BERTを用いて分類タスクをすることで生成文の事実不整合の検出を試みる
疑似データセットを作成し学習することで,不整合検出におけるドメイン適応の重要性を明らかにした
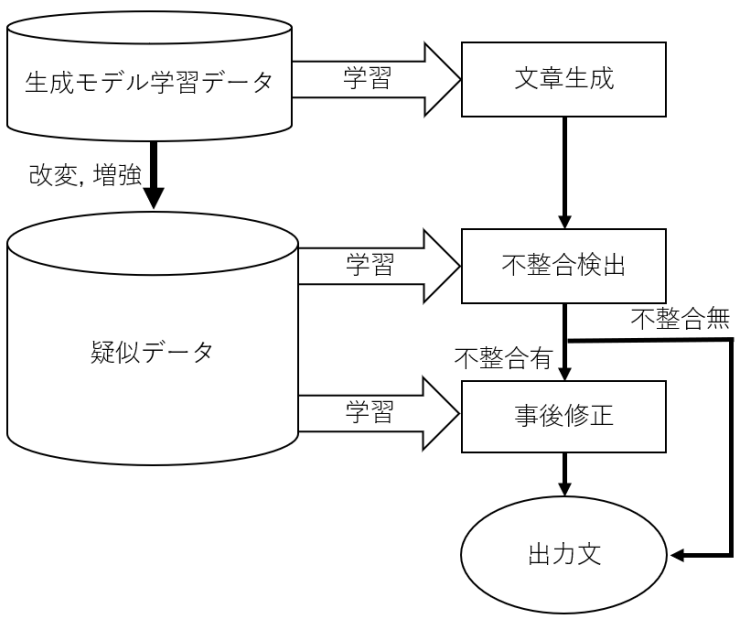
提案手法
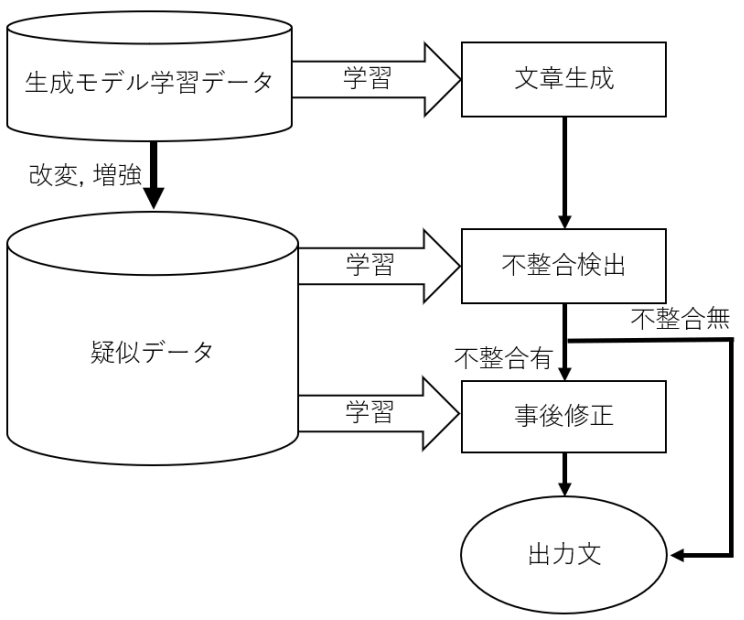
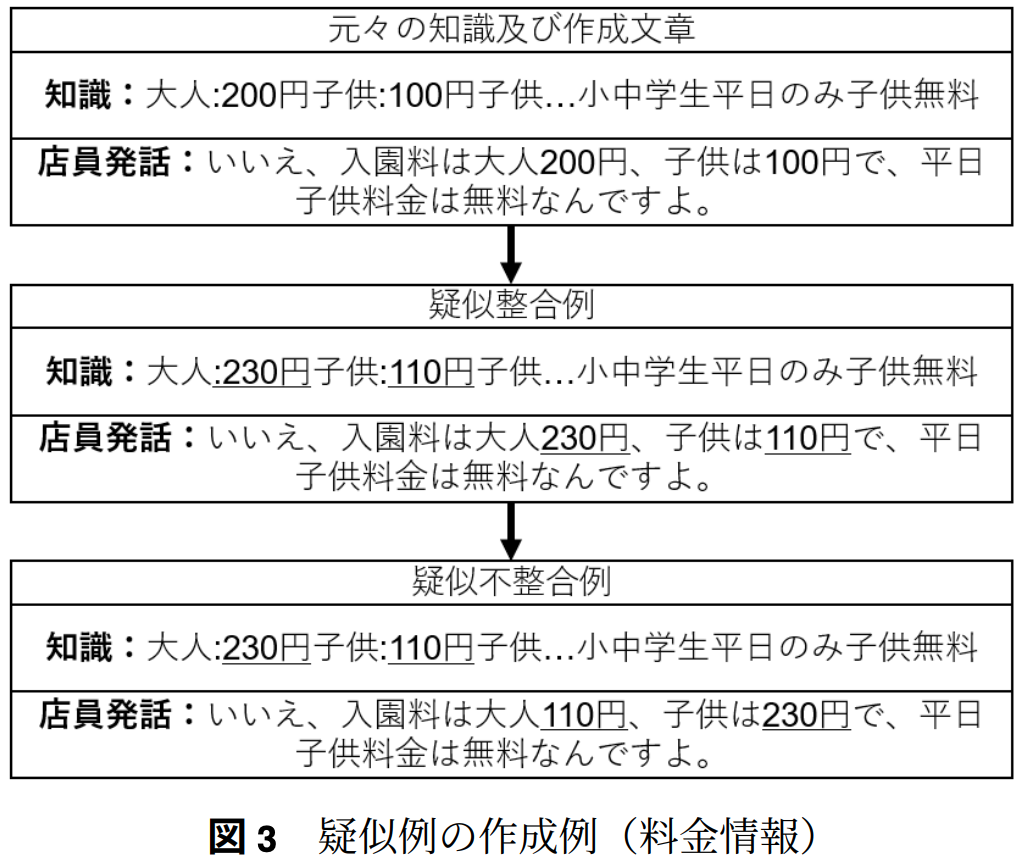
特に数値データに対してロバストなモデルになるよう学習するため,知識に数値が含まれる「料金情報」「アクセス情報」「営業時間情報」の3カテゴリに絞って学習に用いる
疑似例の作成は数値や日付,駅名等を書き換えることで対応
料金,アクセス,営業時間情報で書き以下絵対象がお’異なるため,それぞれ小cleanなる改変方法でデータを書き換え
新規性
旅行ドメインに対して疑似データセットを作成し,それを用いて学習することで,SNLIデータセットを用いた学習に比べて,事実不整合の生成文の検出精度を向上
実験
データセット
事実整合性判定学習データセット
料金,アクセス,営業時間情報について作成した疑似生後売れ,不整合例を集めたデータセット
ニューラル生成文データセット
NTT製TransformerのHobbyistを用いて生成した文章を含むデータセット
Laboro社製BERTをファインチューニング
ベースラインデータセットとして,日本語SNLIデータセット
recallが最良のエポックの重みを最良モデルとして評価
recallが低いモデルは大量の不整合を見逃していることになるため,目的を果たしていないと考えたから
まとめ
提案手法(疑似例を用いたデータセット)は事実不整合検出に有効である
正解できなかった不整合例の内訳
料金7件/アクセス1件/営業時間16件
→ テンプレートの拡充が必要か?